Command Palette
Search for a command to run...
Haoran Wei Yaofeng Sun Yukun Li
초록
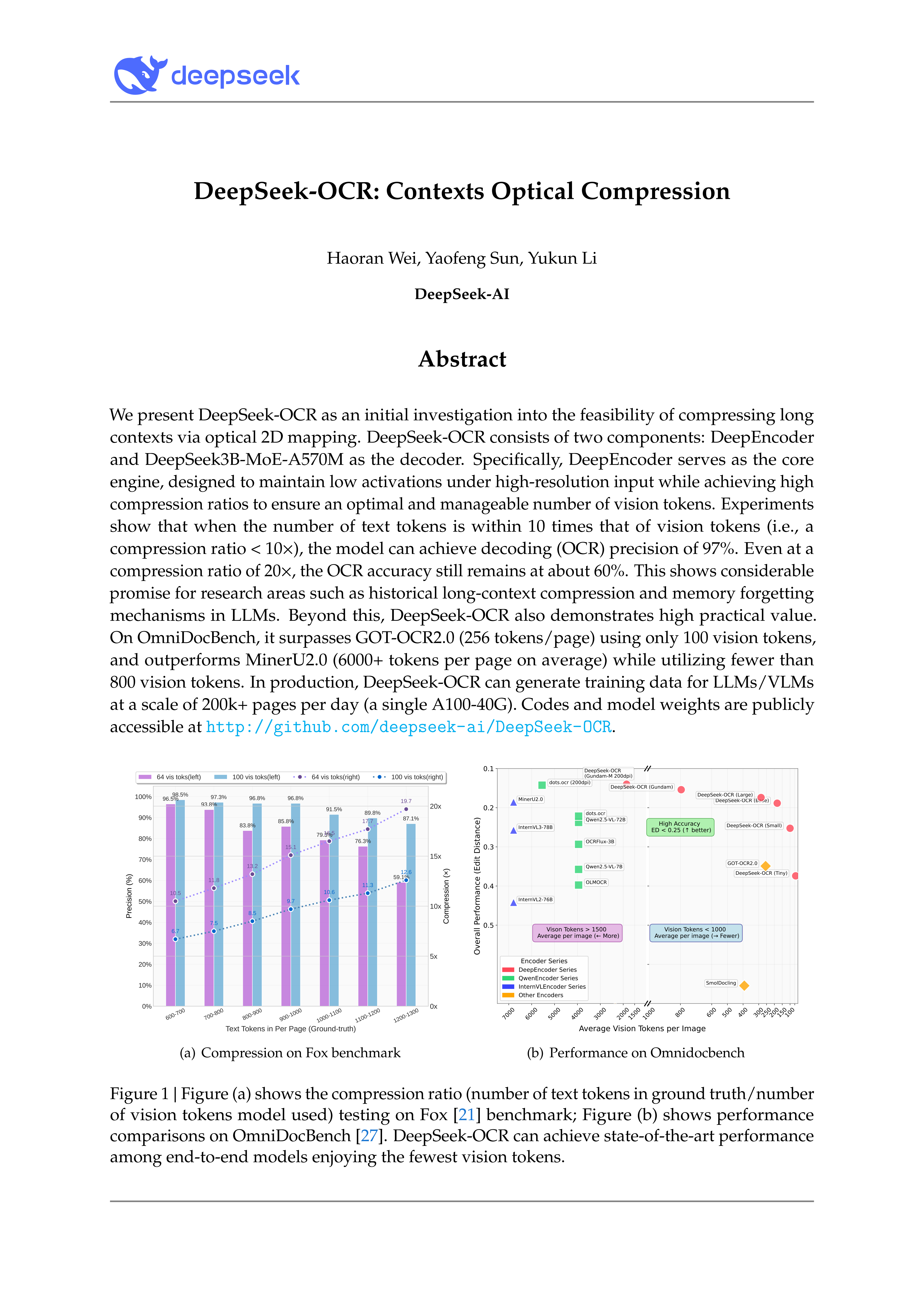
우리는 광학 2차원 매핑을 통한 장문 컨텍스트 압축의 가능성에 대한 초기 탐구로 DeepSeek-OCR를 제안한다. DeepSeek-OCR는 두 가지 구성 요소로 구성된다: 디코더로서의 DeepSeek3B-MoE-A570M과, DeepEncoder이다. 특히 DeepEncoder는 핵심 엔진으로서 고해상도 입력에서도 낮은 활성화를 유지하면서도 높은 압축 비율을 달성하여, 시각 토큰의 수를 최적화하고 관리 가능한 수준으로 유지하도록 설계되었다. 실험 결과, 텍스트 토큰 수가 시각 토큰 수의 10배 이내(즉, 압축 비율 < 10×)일 경우, 모델은 97%의 정확도로 디코딩(OCR)을 수행할 수 있음을 확인했다. 압축 비율이 20×에 이르더라도 OCR 정확도는 약 60%로 유지되며, 이는 역사적 장문 컨텍스트 압축 및 대규모 언어 모델(Large Language Models, LLMs)의 기억 소실 메커니즘 연구 분야에서 큰 잠재력을 보여준다. 더 나아가 DeepSeek-OCR는 높은 실용적 가치도 입증하고 있다. OmniDocBench에서, 100개의 시각 토큰만을 사용하여 GOT-OCR2.0(페이지당 256개 토큰)을 초월했으며, 평균 페이지당 6,000개 이상의 토큰을 사용하는 MinerU2.0보다도 우수한 성능을 달성하면서도 시각 토큰 수는 800개 미만으로 유지했다. 실제 운영 환경에서는 DeepSeek-OCR를 활용해 단일 A100-40G GPU를 통해 하루에 20만 페이지 이상의 LLM/VLM 학습 데이터를 생성할 수 있다. 코드 및 모델 가중치는 공개적으로 http://github.com/deepseek-ai/DeepSeek-OCR 에서 확인 가능하다.