Command Palette
Search for a command to run...

초록
다음은 요청하신 텍스트의 한국어 번역입니다. 기술 전문 용어와 학술적 맥락을 고려하여 번역하였습니다.심층 연구 모델(Deep research models)은 다단계 조사를 수행하여 출처가 명확한 장문(long-form)의 답변을 생성합니다. 그러나 대부분의 공개형 심층 연구 모델은 검증 가능한 보상을 활용한 강화 학습(RLVR, Reinforcement Learning with Verifiable Rewards)을 통해 정답 검증이 용이한 단답형 QA 작업 위주로 훈련되기 때문에, 실제적이고 복잡한 장문 작업으로 확장하는 데는 한계가 있습니다.우리는 이를 해결하기 위해 진화형 루브릭을 활용한 강화 학습(RLER, Reinforcement Learning with Evolving Rubrics)을 도입했습니다. 이 방법은 훈련 과정에서 정책 모델(policy model)과 함께 공동 진화하는 평가 기준(rubrics)을 구축하고 유지합니다. 이를 통해 루브릭은 모델이 새롭게 탐색한 정보를 반영할 수 있으며, 차별화된 온폴리시(on-policy) 피드백을 제공할 수 있게 됩니다.RLER을 기반으로 당사는 개방형(open-ended) 장문 심층 연구를 목적으로 직접 훈련된 최초의 공개 모델인 Deep Research Tulu(DR Tulu-8B)를 개발했습니다. 과학, 헬스케어 및 일반 분야를 아우르는 4가지 장문 심층 연구 벤치마크에서 DR Tulu는 기존의 공개형 심층 연구 모델을 크게 능가하는 성능을 보였으며, 독점적인(proprietary) 상용 심층 연구 시스템과 대등하거나 그 이상의 성능을 기록했습니다. 동시에 모델의 크기는 훨씬 작고 쿼리당 비용도 현저히 저렴합니다.후속 연구를 촉진하기 위해 당사는 심층 연구 시스템을 위한 새로운 MCP 기반 에이전트 인프라를 포함하여 모든 데이터, 모델 및 코드를 공개합니다.
Summarization
Researchers from the University of Washington, Allen Institute for AI, MIT, et al. introduce Deep Research Tulu (DR Tulu-8B), an open model that leverages Reinforcement Learning with Evolving Rubrics (RLER) to generate dynamic, on-policy feedback for long-form tasks, thereby matching the performance of proprietary systems in complex domains like science and healthcare.
Introduction
Deep research models are designed to execute complex tasks by planning, searching, and synthesizing information from diverse sources, yet training open-source versions remains difficult due to the challenge of verifying long-form, open-ended responses. While proprietary systems have advanced significantly, reliable evaluation requires access to dynamic world knowledge rather than static metrics, creating a bottleneck for current training methodologies.
Limitations of Prior Work Existing open models typically rely on training-free prompting strategies or are trained indirectly using short-form question answering as a proxy for deep research. These approaches often depend on fixed, hard-coded search tools and static evaluation rubrics, which fail to capture the nuance of complex reasoning or provide the verifiable citations necessary for rigorous academic and professional tasks.
Main Contribution The authors introduce Deep Research Tulu (DR Tulu-8B), the first open model directly trained for long-form deep research tasks. Their primary methodological contribution is Reinforcement Learning with Evolving Rubrics (RLER), a training framework where evaluation criteria co-evolve with the policy model. This allows the system to generate dynamic, on-policy feedback that contrasts specific model responses against external evidence found during the search process.
Key Innovations and Advantages
- Dynamic Rubric Evolution: RLER constructs new rubrics at each training step by analyzing the model's search traces, preventing reward hacking and ensuring feedback adapts to the model's expanding knowledge base.
- High Efficiency and Performance: Despite being an 8B parameter model, DR Tulu outperforms larger open models (up to 30B) and matches proprietary systems like OpenAI Deep Research while reducing inference costs by nearly three orders of magnitude.
- Adaptive Tool Usage: The model learns to autonomously select the most appropriate search tools (e.g., switching between general web search and academic paper repositories) and generates comprehensive reports with accurate, evidence-linked citations.
Dataset
The authors construct a specialized dataset of approximately 16,000 trajectories to address the "cold start" problem, teaching the model to plan, invoke tools, and format citations before Reinforcement Learning (RL). The dataset construction involves the following components and processes:
- Data Composition: The dataset combines long-form, open-ended information-seeking queries with short-form, verifiable QA tasks. This mixture ensures the model learns to adapt its style without overfitting to a single task type.
- Long-form Sources: Prompts are derived from SearchArena (real-world user-assistant conversations) and OpenScholar (scientific research queries). The authors apply an LLM-based filter where GPT-5 rates prompts on a 1 to 5 scale for complexity, retaining approximately 10% of SearchArena and 20% of OpenScholar queries.
- Short-form Sources: To encourage precision, the authors sample questions from HotpotQA, TaskCraft, WebWalker-Silver, MegaScience, PopQA, and TyDi QA. They also generate synthetic questions in the style of BrowseComp using GPT-4.1.
- Trajectory Generation: The authors use GPT-5 as a teacher model to generate end-to-end trajectories. These include explicit "thinking" tokens, tool invocations (Google Search, Web Browse, Paper Search), and final answers with citations.
- Data Transformation: For Ai2 ScholarQA, the authors transform static retrieval data into iterative search trajectories. They use GPT-4.1 to generate sub-queries based on section text and cited papers, interleaving these with reasoning steps to simulate a multi-step research process.
- Rejection Sampling: The team applies strict filtering to the generated data. They discard trajectories that fail to follow tool-calling formats or omit answer tags. For short-form tasks, they retain only those examples where the generated answer matches the gold standard, verified via F1 overlap (>0.9) or an LLM judge.
- RL Data Separation: Distinct from the SFT set, the authors curate a separate set of high-quality prompts from SearchArena and OpenScholar for the RL stage, generating rubrics using GPT-4.1-mini based on retrieved search results.
Method
The authors leverage a reinforcement learning framework with evolving rubrics (RLER) to train deep research models that can perform long-form reasoning and information synthesis using external tools. The core of this approach is a policy model, denoted as πθ, which operates in an autoregressive manner over a sequence of actions and content. The model's action space includes four distinct types: think, which generates internal reasoning; tool, which invokes external search tools such as web browsing or paper search; answer, which produces the final response; and cite, which wraps claims in citation tags. The policy interacts with an environment that provides access to various search tools, enabling it to retrieve and incorporate external knowledge into its responses. The training process is designed to optimize the model's ability to generate high-quality, well-supported answers by using a dynamic set of evaluation criteria, or rubrics, that adapt over time.

The framework begins with a set of persistent rubrics, which are generated for each training instance by retrieving relevant documents from the internet and using a language model to produce a set of initial evaluation criteria. These rubrics are grounded in real-world knowledge and are intended to be stable throughout the training process. During each training step, the policy model generates multiple rollouts, or response trajectories, for a given prompt. These rollouts are then used to generate a new set of evolving rubrics. The generation process involves contrasting the different responses to identify both positive aspects—such as new, relevant knowledge explored by the model—and negative aspects, such as undesirable behaviors like reward hacking or verbatim copying. This process ensures that the rubrics are tailored to the current policy's behaviors and are grounded in the knowledge it has explored.

The evolving rubrics are added to a rubric buffer, which is managed to maintain a compact and informative set. After each training step, the model scores all generated responses using the current set of rubrics, and the standard deviation of the rewards for each rubric is computed. Rubrics with zero variance are removed, as they offer no discriminative power, and the remaining rubrics are ranked by their standard deviation. Only the top Kmax rubrics with the highest variance are retained, ensuring that the most informative and discriminative criteria are used for evaluation. This dynamic management of the rubric buffer allows the evaluation criteria to co-evolve with the policy, providing on-policy feedback that the model can effectively learn from.

Experiment
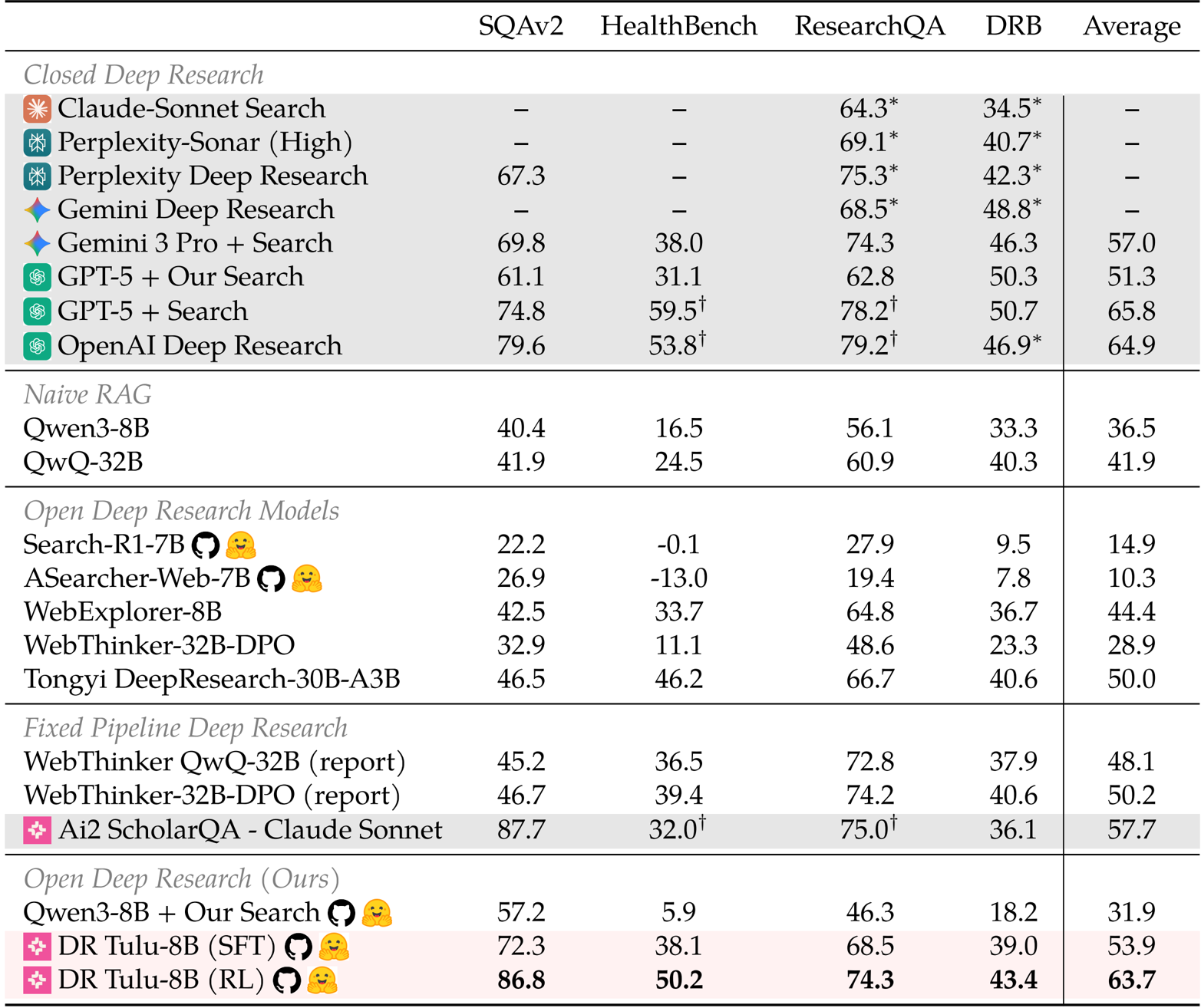
- Evaluated DR Tulu-8B on four long-form benchmarks (HealthBench, ResearchQA, SQAv2, DeepResearchBench), where it outperformed existing open deep research models by 13.7 to 53.4 points on average.
- Compared performance against proprietary systems, showing that DR Tulu-8B matches or surpasses OpenAI Deep Research and Perplexity on SQAv2 while reducing query costs to approximately USD 0.0018.
- Assessed the impact of Reinforcement Learning with Evolving Rubrics (RLER), finding that it improved rubric coverage by 8.2 points and boosted citation precision and recall on SQAv2 by 23.3 and 22.1 points, respectively.
- Validated performance on a novel GeneticDiseasesQA dataset, where the model surpassed Ai2 ScholarQA and Gemini 3 + Search in overall scores and matched proprietary models in evidence quality and synthesis.
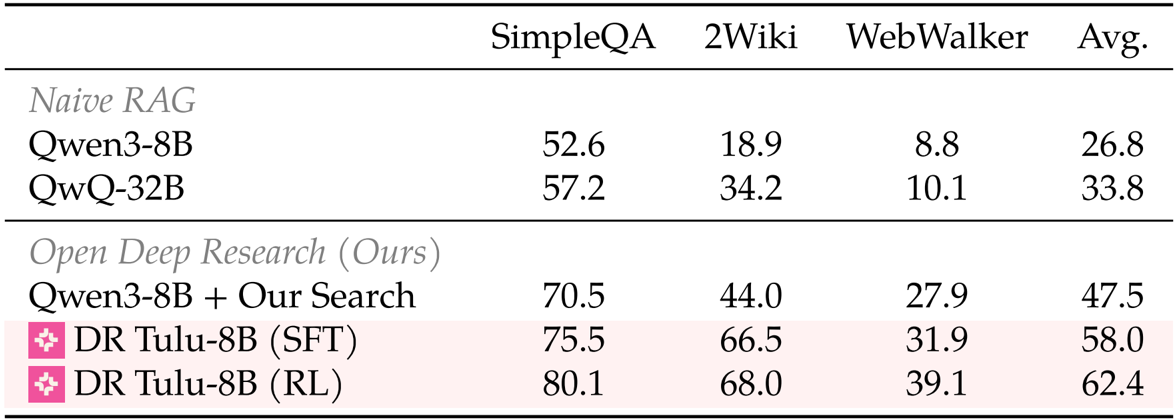
- Tested generalization on short-form QA tasks (SimpleQA, 2Wiki), revealing that RL training improved average accuracy by 4.4 points despite the focus on long-form optimization.
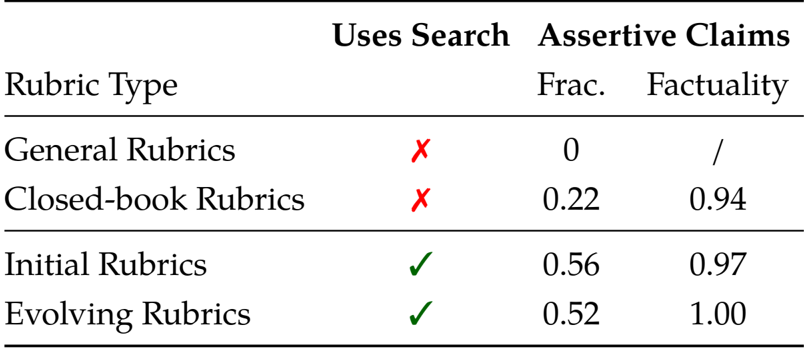
- Conducted ablation studies on training methodologies, demonstrating that search-based and evolving rubrics are over 50% more assertive than naive methods and that combining long-form and short-form SFT data prevents performance degradation.
The authors use search-based rubrics to generate more specific and factual evaluation criteria compared to general or closed-book rubrics. Results show that initial and evolving rubrics achieve higher fractions of assertive claims and factuality, with evolving rubrics reaching perfect factuality scores, indicating they are more effective for training deep research agents.
The authors use a combination of search-based and evolving rubrics to improve the quality of deep research agents, with results showing that DR Tulu-8B (RL) outperforms all open deep research models and matches or exceeds proprietary systems on long-form benchmarks. The model achieves the highest average score of 63.7 across four evaluation datasets, demonstrating superior performance in both content quality and citation accuracy compared to baselines.
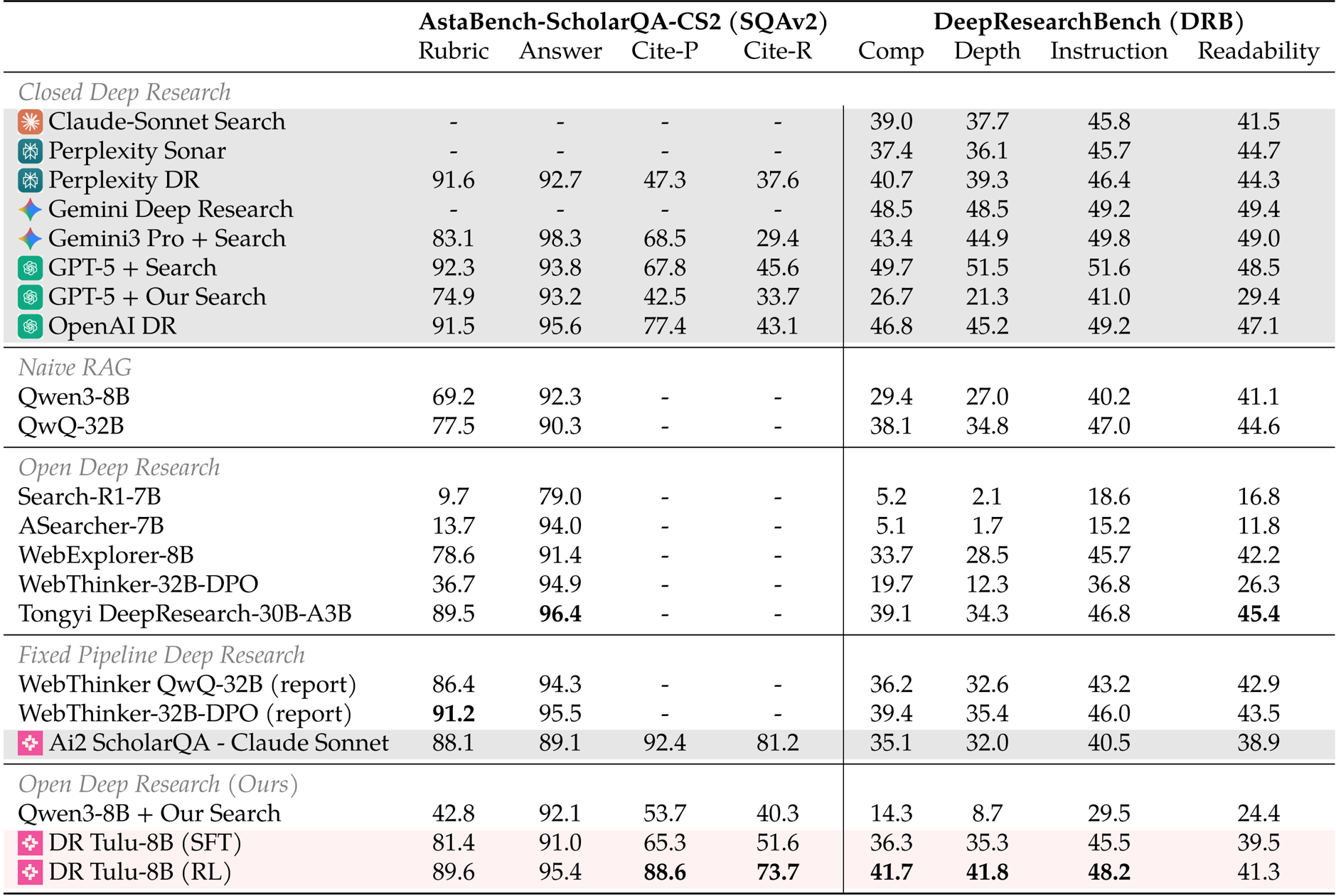
The authors use the table to compare the performance of various deep research models on two long-form benchmarks, AstaBench-ScholarQA-CS2 (SQAv2) and DeepResearchBench (DRB). Results show that DR Tulu-8B (RL) achieves the highest scores on both benchmarks, outperforming all other open and closed deep research models, including larger proprietary systems like GPT-5 and Gemini3 Pro. The model also demonstrates strong performance on citation metrics, with the RL version achieving 88.6 on Cite-P and 73.7 on Cite-R on SQAv2, significantly surpassing most baselines.
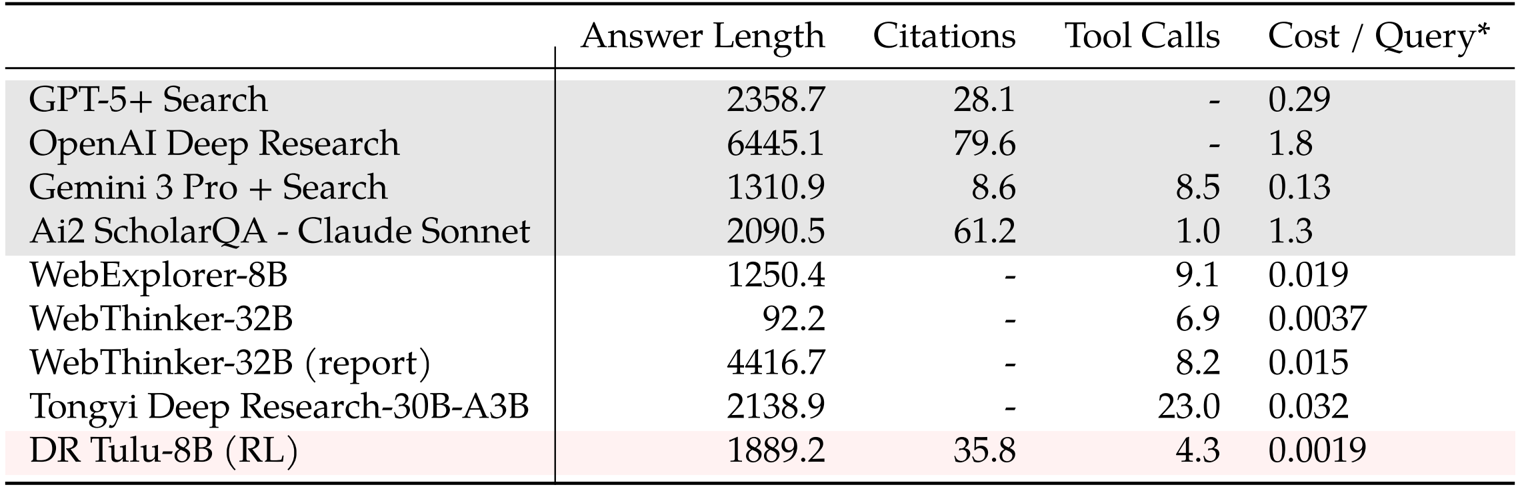
The authors use the table to compare the performance and cost of various deep research systems across metrics such as answer length, citations, tool calls, and cost per query. Results show that DR Tulu-8B (RL) achieves a balanced performance with moderate answer length, 35.8 citations, and 4.3 tool calls, while maintaining a significantly lower cost of $0.0019 per query compared to proprietary systems like OpenAI Deep Research and GPT-5 + Search, which cost 1.8 and 0.29 per query respectively.
The authors use a short-form QA evaluation to assess the generalization of their deep research models beyond long-form tasks. Results show that DR Tulu-8B (RL) achieves the highest average score of 62.4 across SimpleQA, 2Wiki, and WebWalker, outperforming both the base Qwen3-8B and QwQ-32B models as well as the SFT version of DR Tulu. This indicates that the RL training, despite being applied only to long-form tasks, improves performance on short-form QA benchmarks.