Command Palette
Search for a command to run...

초록
다음은 요청하신 텍스트의 한국어 번역입니다. 과학 기술 분야의 전문적이고 학술적인 문체로 번역되었습니다.대규모 언어 모델(LLM)의 다양한 작업에서 테스트 시간(test-time) 연산을 확장하면 성능이 향상되며, 이러한 접근 방식은 도구 증강(tool-augmented) 에이전트로도 확장되었습니다. 이러한 에이전트에게 있어 스케일링이란 단순히 토큰 단위의 '사고(thinking)' 과정뿐만 아니라, 도구 호출(tool calls)을 통한 '행동(acting)'까지 포함하는 개념입니다. 도구 호출의 횟수는 에이전트와 외부 환경 간의 상호작용 범위를 직접적으로 제한합니다. 그러나 연구 결과, 에이전트에게 단순히 더 많은 도구 호출 예산을 부여하는 것만으로는 성능 향상으로 이어지지 않음이 밝혀졌습니다. 이는 에이전트에게 '예산 인식(budget awareness)' 능력이 결여되어 있어 성능 한계(performance ceiling)에 빠르게 도달하기 때문입니다.이러한 문제를 해결하기 위해, 본 연구에서는 웹 검색 에이전트에 초점을 맞추어 명시적인 도구 호출 예산 제약 하에서 에이전트를 효과적으로 확장(scale)하는 방법을 연구합니다. 우선, 에이전트에게 지속적인 예산 인식 능력을 제공하여 간단하면서도 효과적인 확장을 가능하게 하는 경량 플러그인인 'Budget Tracker'를 제안합니다. 더 나아가, 남은 자원(resources)을 기반으로 유망한 단서를 '더 깊이 파고들지(dig deeper)', 아니면 새로운 경로로 '방향을 선회할지(pivot)'를 결정함으로써 계획 및 검증 전략을 동적으로 조정하는 고급 프레임워크인 BATS(Budget Aware Test-time Scaling)를 개발하였습니다.또한, 비용 대비 성능의 확장성을 통제된 환경에서 분석하기 위해, 토큰 소비량과 도구 사용량을 통합적으로 고려하는 단일 비용 지표(unified cost metric)를 정식화하였습니다. 본 연구는 예산 제약이 있는 에이전트에 대한 최초의 체계적인 연구로서, 예산을 인식하는 방법론이 더 우수한 스케일링 곡선을 나타내며 비용-성능 파레토 프론티어(Pareto frontier)를 확장함을 입증합니다. 결론적으로, 본 연구는 도구 증강 에이전트의 스케일링에 대한 보다 투명하고 원칙적인 이해를 돕는 실증적 통찰을 제공합니다.
Summarization
Researchers from UC Santa Barbara, Google, and New York University introduce BATS, a framework for tool-augmented web search agents that leverages a Budget Tracker to dynamically adapt planning and verification strategies based on remaining resources, effectively pushing the cost-performance Pareto frontier beyond the limits of simple tool-call scaling.
Introduction
Scaling test-time compute has proven effective for improving LLM reasoning, prompting a shift toward applying these strategies to tool-augmented agents that interact with external environments like search engines. In this context, performance relies not just on internal "thinking" (token generation) but also on "acting" (tool calls), where the number of interactions determines the depth and breadth of information exploration.
However, standard agents lack inherent budget awareness; they often perform shallow searches or fail to utilize additional resources effectively, hitting a performance ceiling regardless of the allocated budget. Unlike text-only reasoning where token counts are the primary constraint, tool-augmented agents face the unique challenge of managing external tool-call costs without explicit signals to spend them strategically.
To address this, the authors introduce a systematic framework for budget-constrained agent scaling, focusing on maximizing performance within a fixed allowance of tool calls and token consumption.
Key innovations include:
- Budget Tracker: A lightweight, plug-and-play module compatible with standard orchestration frameworks that provides agents with a continuous signal of resource availability to prevent inefficient spending.
- BATS Framework: A dynamic system that adapts planning and verification strategies in real time, allowing the agent to decide whether to "dig deeper" into a lead or "pivot" to alternative paths based on the remaining budget.
- Unified Cost Metric: A formalized method that jointly accounts for the economic costs of both internal token consumption and external tool interactions, enabling a transparent evaluation of the true cost-performance trade-off.
Method
The authors propose BATS, a Budget-Aware Test-time Scaling framework for tool-augmented agents operating under explicit budget constraints. The core design principle of BATS is budget awareness, which is integrated throughout the agent's reasoning and action selection process. As shown in the framework diagram, the agent begins by receiving a question and a per-tool budget. The process starts with internal reasoning, which is augmented by a structured planning module that generates a tree-structured plan. This plan acts as a dynamic checklist, recording step status, resource usage, and allocation, and guiding future actions. The agent then iterates through a loop of reasoning, tool calls, and processing tool responses, continuously updating its internal state based on the new information and the remaining budget. When a candidate answer is proposed, a self-verification module evaluates the reasoning trajectory and the current budget status. This module performs a constraint-by-constraint backward check to assess whether the answer satisfies the question's requirements. Based on this analysis and the remaining budget, the verifier makes a strategic decision: to declare success if all constraints are satisfied, to continue exploration if the plan is salvageable and budget permits, or to pivot to a new direction if the current path is a dead end or the budget is insufficient. If the decision is to continue or pivot, the module generates a concise summary of the trajectory, which replaces the raw history in context to reduce length and maintain grounding. The iterative process terminates when any budgeted resource is exhausted. Finally, an LLM-as-a-judge selects the best answer from all verified attempts. 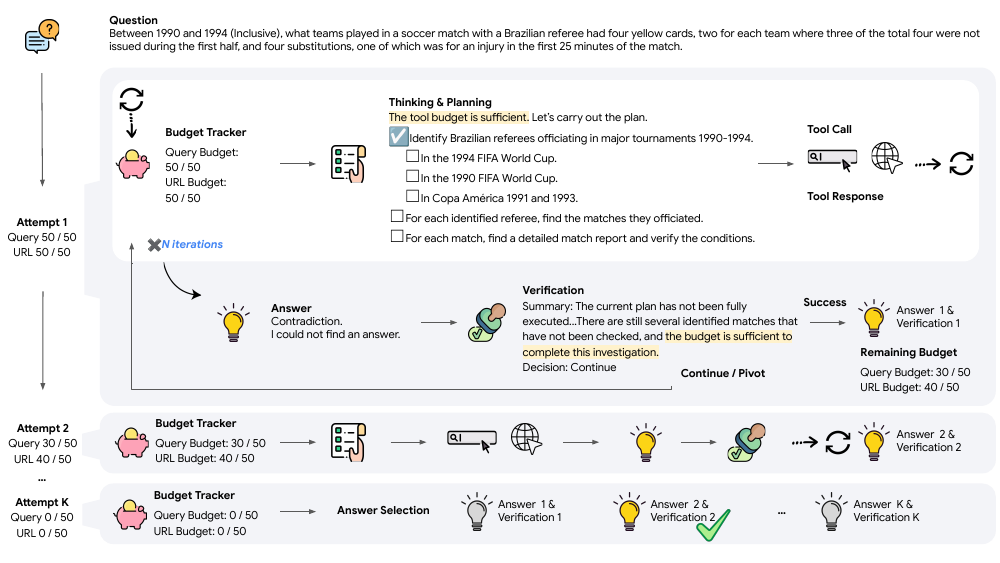
The BATS framework incorporates budget awareness through a lightweight, plug-and-play module called the Budget Tracker. This module is designed to be a simple, prompt-level addition that surfaces real-time budget states within the agent's reasoning loop. At the beginning of the process, the tracker provides a brief policy guideline describing the budget regimes and corresponding tool-use recommendations. At each subsequent iteration, the tracker appends a budget status block showing the remaining and used budgets for each available tool. This persistent awareness enables the agent to condition its subsequent reasoning steps on the updated resource state, shaping its planning, tool-use strategy, and verification behavior. The authors demonstrate that this explicit budget signal allows the model to internalize resource constraints and adapt its strategy without requiring additional training. 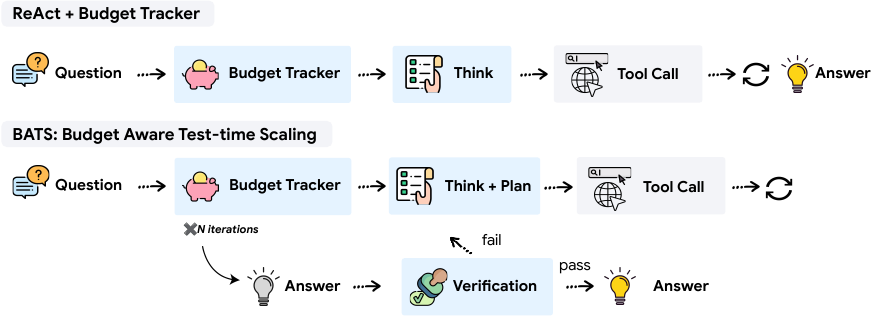
Budget-aware planning in BATS is achieved through a combination of constraint decomposition and structured dynamic planning. The agent is instructed to first perform constraint decomposition, categorizing the clues in the question into two types: exploration, which expands the candidate space, and verification, which validates specific properties. This initial step is critical for selecting an appropriate starting point and conserving budget. The agent then generates and maintains an explicit, tree-structured plan throughout execution. This plan acts as a dynamic checklist, recording step status, resource usage, and allocation, while guiding future actions. Completed, failed, or partial steps are never overwritten, ensuring a full execution trace and preventing redundant tool calls. The planning module adjusts exploration breadth and verification depth based on the current remaining budget, allowing BATS to maintain a controlled and interpretable search process while efficiently allocating available tool calls across exploration and verification subtasks. 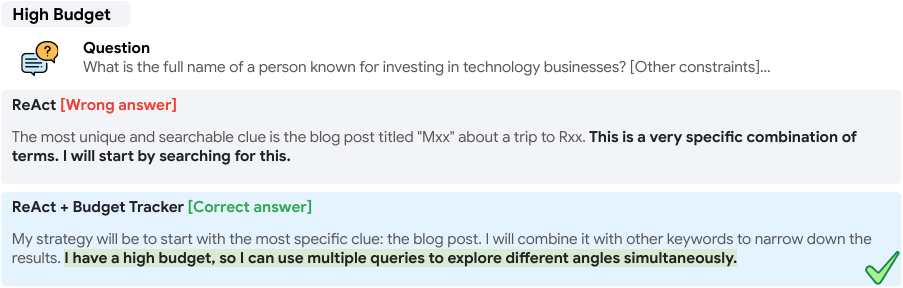
The self-verification module in BATS re-evaluates the reasoning trajectory and corresponding resource usage to make a strategic decision. This process begins with a constraint-by-constraint backward check, assessing each constraint to determine if it has been satisfied, contradicted, or remains unverifiable. Based on this analysis and the budget status, the module makes one of three decisions: SUCCESS if all constraints are satisfied; CONTINUE if several constraints remain unverifiable but the trajectory appears promising and the budget is sufficient; or PIVOT if contradictions are identified or the remaining budget cannot support further investigation. When the decision is to continue or pivot, the module generates a concise summary that replaces the raw trajectory in context. This includes key reasoning steps, intermediate findings, failure causes, and suggestions for optimization. By compressing the reasoning trajectory into a compact and informative summary, the verifier reduces context length while ensuring that subsequent attempts remain grounded in previously acquired information. This allows BATS to terminate useless trajectories early, continue promising ones efficiently, and maintain reliable progress toward the correct answer within strict budget constraints. 
Experiment
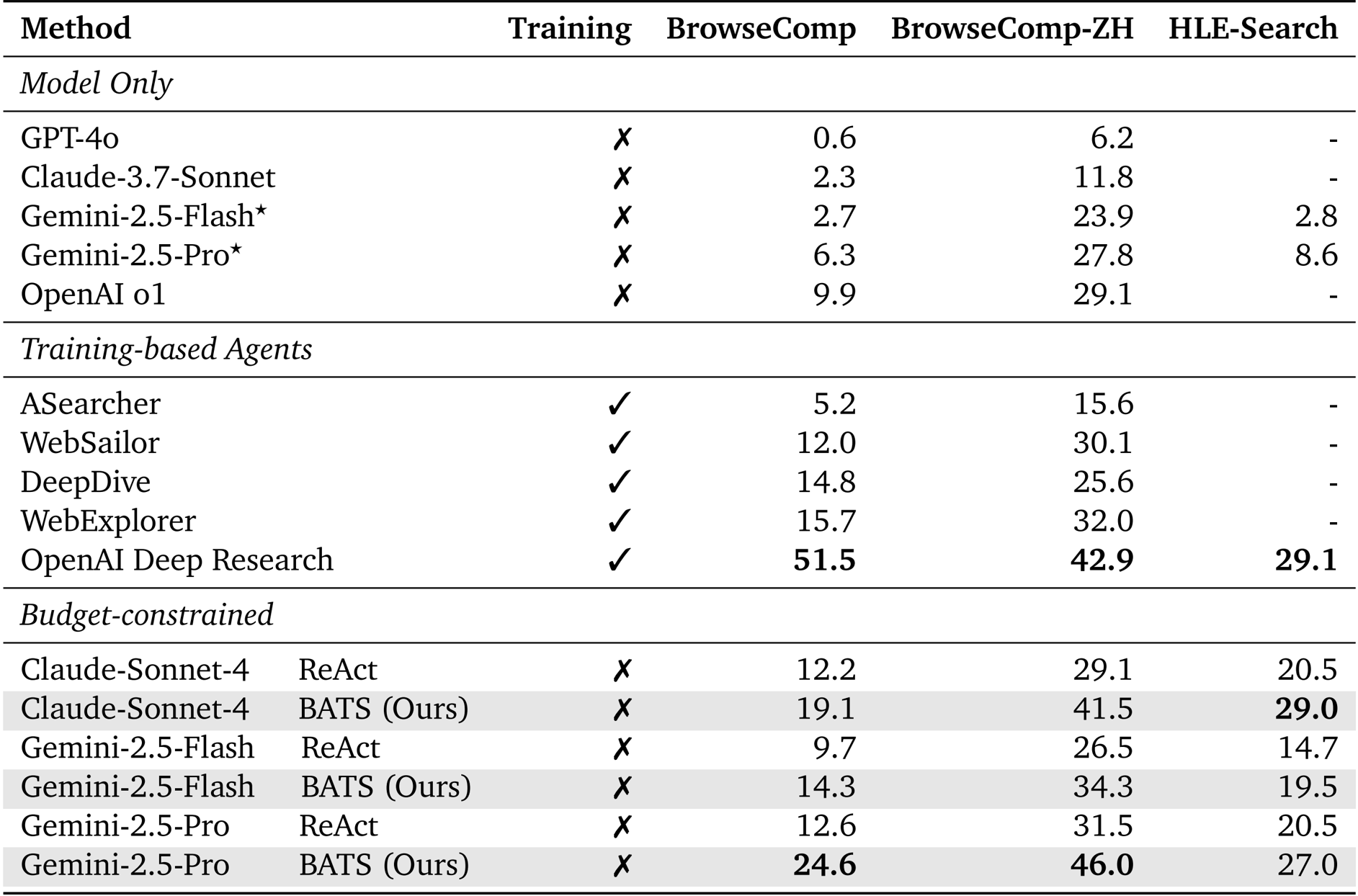
- Evaluated the Budget Tracker and BATS framework on BrowseComp, BrowseComp-ZH, and HLE-Search datasets, comparing them against ReAct and general-purpose base models.
- BATS consistently outperformed baselines using Gemini-2.5-Pro, achieving 24.6% accuracy on BrowseComp and 46.0% on BrowseComp-ZH without additional fine-tuning.
- The Budget Tracker demonstrated superior efficiency, matching ReAct's accuracy while using 40.4% fewer search calls and reducing overall costs by 31.3%.
- In test-time scaling experiments, the method avoided the performance plateaus observed in ReAct, successfully leveraging larger budgets to improve results in both sequential and parallel settings.
- Ablation studies validated the necessity of planning and verification modules, showing that removing verification caused a significant accuracy drop from 18.7% to 15.4% on BrowseComp.
- Cost-efficiency analysis revealed that BATS reached over 37% accuracy for approximately 0.23,whereastheparallelmajorityvotebaselinerequiredover0.50 to achieve comparable results.
The authors use the Budget Tracker to enhance the performance of ReAct-based agents under constrained tool budgets. Results show that adding the Budget Tracker consistently improves accuracy across all models and datasets, demonstrating that explicit budget awareness enables more strategic and effective tool use.
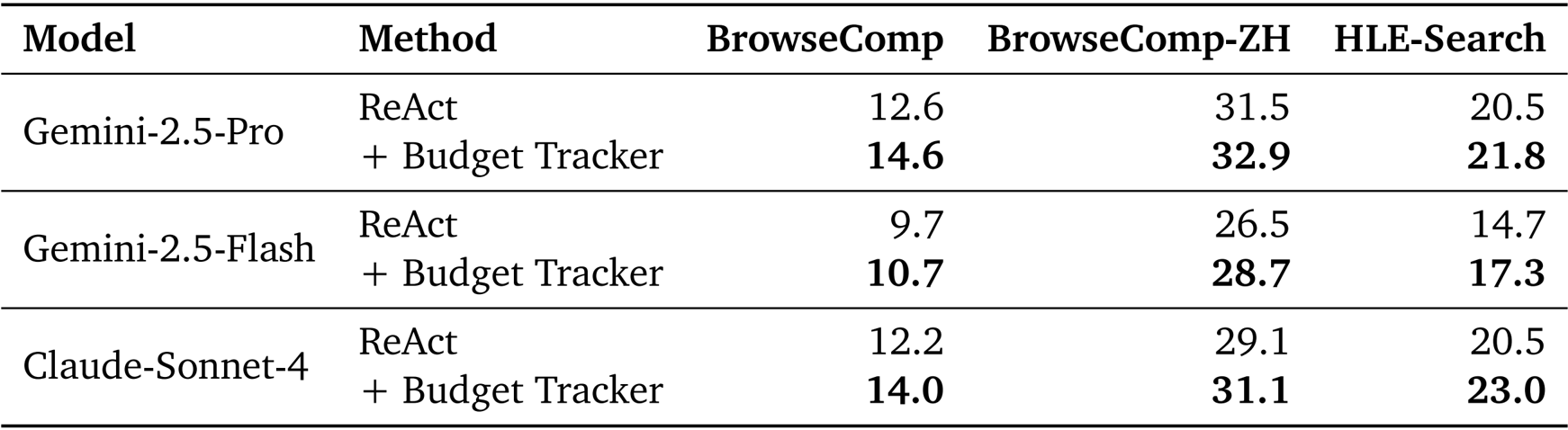
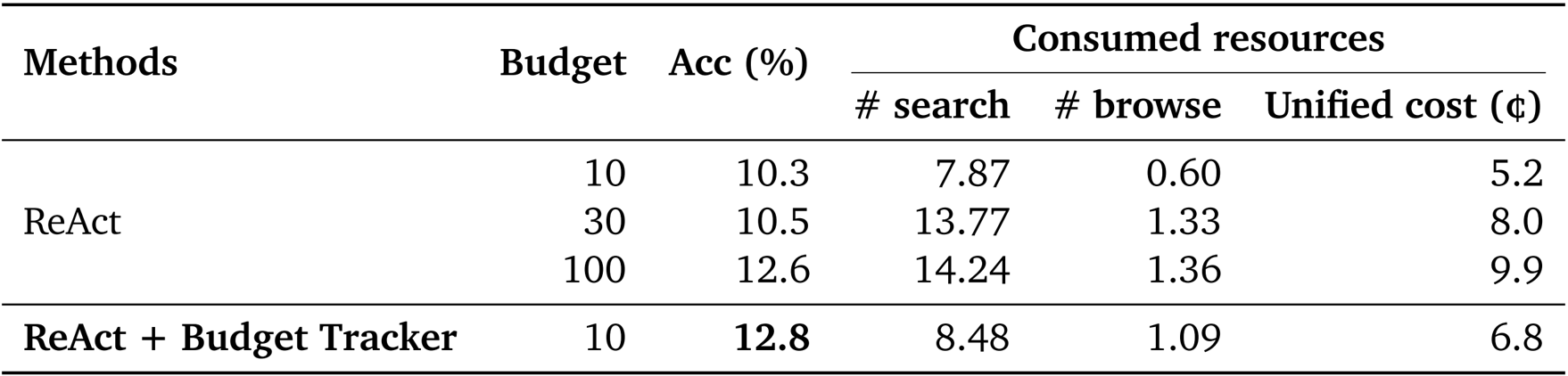
Results show that ReAct + Budget Tracker achieves higher accuracy (12.8%) than ReAct with a budget of 100 (12.6%) while using fewer search and browse tool calls and a lower unified cost. This demonstrates that explicit budget awareness enables more efficient and effective use of resources, allowing the agent to achieve better performance with significantly reduced tool usage and cost.
The authors use the Budget Tracker to enhance agent performance under constrained tool budgets, showing that BATS consistently outperforms the ReAct baseline across all datasets and models. Results show that BATS achieves higher accuracy with fewer tool calls and lower unified costs, demonstrating more efficient resource utilization and improved scalability.
The authors use BATS, a budget-aware framework, to evaluate the impact of its planning and verification modules on performance across three datasets. Results show that removing either module reduces accuracy, with the verification module having a more significant effect, particularly on BrowseComp, indicating both components are essential for effective agent behavior.