Command Palette
Search for a command to run...
Yang Luo Xuanlei Zhao Baijiong Lin Lingting Zhu Liyao Tang Yuqi Liu Ying-Cong Chen Shengju Qian Xin Wang Yang You
초록
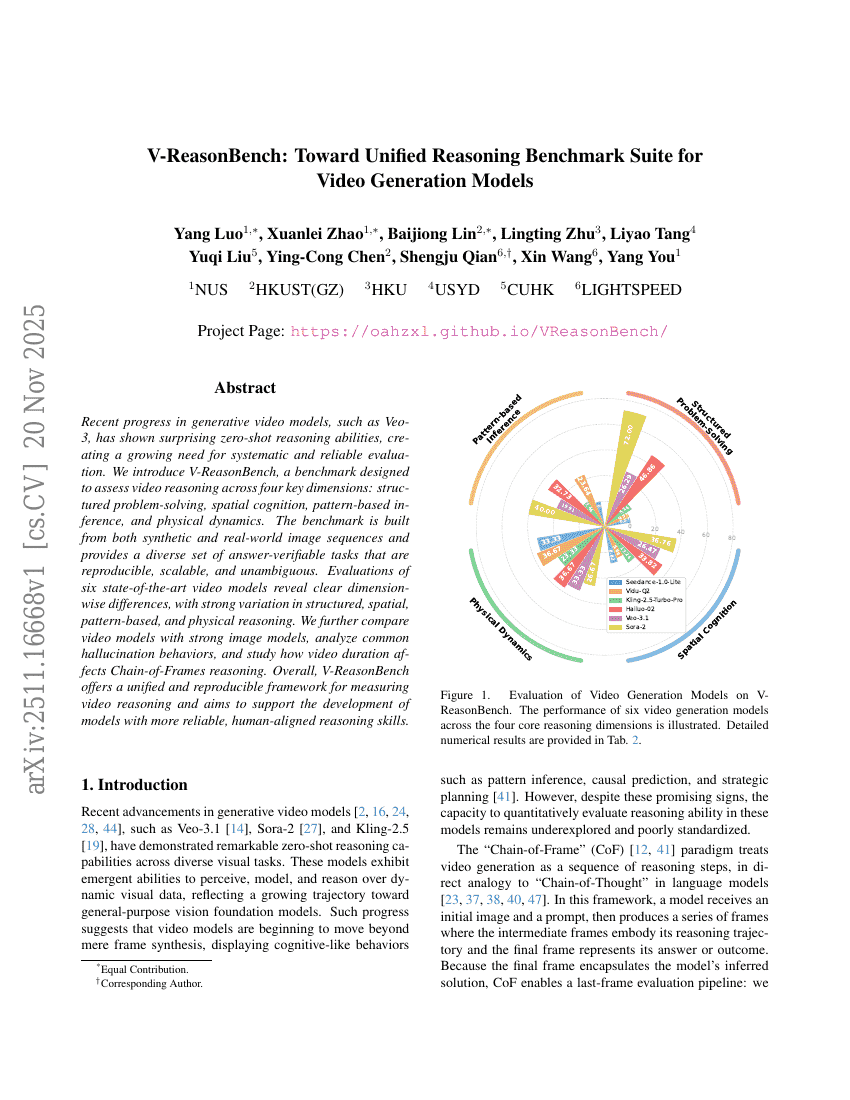
최근 베오-3(Veo-3)와 같은 생성형 비디오 모델의 발전은 놀라운 제로샷 추론 능력을 보여주며, 체계적이고 신뢰할 수 있는 평가 수요가 점차 증가하고 있다. 본 연구에서는 구조적 문제 해결, 공간 인지, 패턴 기반 추론, 물리적 동역학의 네 가지 핵심 차원에서 비디오 추론 능력을 평가할 수 있도록 설계된 V-ReasonBench를 제안한다. 이 벤치마크는 합성 이미지 시퀀스와 실제 세계 이미지 시퀀스를 기반으로 구성되며, 재현 가능하고 확장 가능하며 모호하지 않은 검증 가능한 답변을 제공하는 다양한 과제를 포함한다. 최신 6개의 비디오 모델에 대한 평가 결과, 구조적, 공간적, 패턴 기반, 물리적 추론 능력 측면에서 명확한 차이가 드러났다. 또한, 강력한 이미지 모델과의 비교를 통해 공통된 환각( hallucination) 행동을 분석하고, 비디오 길이가 프레임 체인 추론(chain-of-frames reasoning)에 미치는 영향을 탐구하였다. 종합적으로 V-ReasonBench는 비디오 추론 능력을 통합적이고 재현 가능한 프레임워크로 측정할 수 있도록 지원하며, 더 신뢰성 높고 인간 중심의 추론 능력을 갖춘 모델 개발을 목표로 한다.