Command Palette
Search for a command to run...

초록
우리는 단일 이미지로부터 기하학적 형태, 질감, 배치 정보를 예측하는 시각적으로 기반된 3차원 객체 재구성용 생성 모델인 SAM 3D를 제안한다. SAM 3D는 일반적인 자연 이미지에서 자주 발생하는 가림 현상과 장면의 혼잡함 속에서도, 맥락에서 제공되는 시각적 인식 신호가 더 중요한 역할을 하는 환경에서 뛰어난 성능을 발휘한다. 이를 위해 객체의 형태, 질감, 자세를 정확히 주석화하기 위한 인간과 모델이 협업하는 루프 구조의 파이프라인을 개발하였으며, 이로써 전례 없는 규모의 시각적으로 기반된 3차원 재구성 데이터를 확보하였다. 이러한 데이터를 기반으로 합성 데이터 전훈련과 실제 세계 데이터 정렬을 결합한 현대적인 다단계 학습 프레임워크를 활용하여, 3차원 분야의 ‘데이터 장벽’을 돌파하였다. 실제 세계의 객체와 장면에 대한 인간 선호도 테스트에서 최근 연구 대비 최소 5:1 이상의 우수성 확보를 확인하였으며, 코드 및 모델 가중치, 온라인 데모, 그리고 실제 환경에서의 3차원 객체 재구성에 도전적인 새로운 벤치마크를 공개할 예정이다.
Summarization
Meta Superintelligence Labs提出了一种名为SAM 3D的生成式模型,通过结合人类与模型协同标注的海量视觉地基3D数据,实现了从单张自然图像中联合预测物体几何、纹理与布局,突破了真实场景下3D重建的“数据壁垒”,在复杂遮挡与场景杂乱条件下显著优于现有方法,为开放世界3D内容生成提供了新范式。
Introduction
Authors address the challenge of 3D reconstruction from a single image—a critical task for applications in AR/VR, robotics, and digital content creation—where traditional multi-view methods fall short in real-world scenarios with clutter, occlusion, and complex layouts. While prior work relies on synthetic data or isolated objects, it struggles to generalize to diverse, natural scenes due to the scarcity of real-world 3D-annotated images. To overcome this, the authors introduce SAM 3D, a generative foundation model that reconstructs full 3D shape, texture, and camera layout from a single image. They propose a novel data engine leveraging a model-in-the-loop (MITL) pipeline, where human annotators select or refine 3D proposals generated by the model, creating a self-improving feedback loop. This enables scalable, high-quality 3D annotations for real-world images, bridging the synthetic-to-real gap.
Key innovations include:
- Synthetic-to-Real Transfer via Multi-Stage Training: A three-phase pipeline combining synthetic pretraining, semi-synthetic mid-training, and real-world post-training with human-in-the-loop refinement, enabling strong generalization to complex, real-world scenes.
- Human-in-the-Loop Data Engine (MITL): A scalable annotation framework where humans select or correct 3D proposals from model-generated candidates, creating a virtuous cycle that improves both data quality and model performance.
- Real-World Benchmark (SA-3DAO): A new, diverse benchmark of 1,000 real-world image-3D pairs across challenging categories (e.g., animals, structures, rare objects), providing an expert-annotated gold standard for evaluating real-world 3D reconstruction.
Dataset
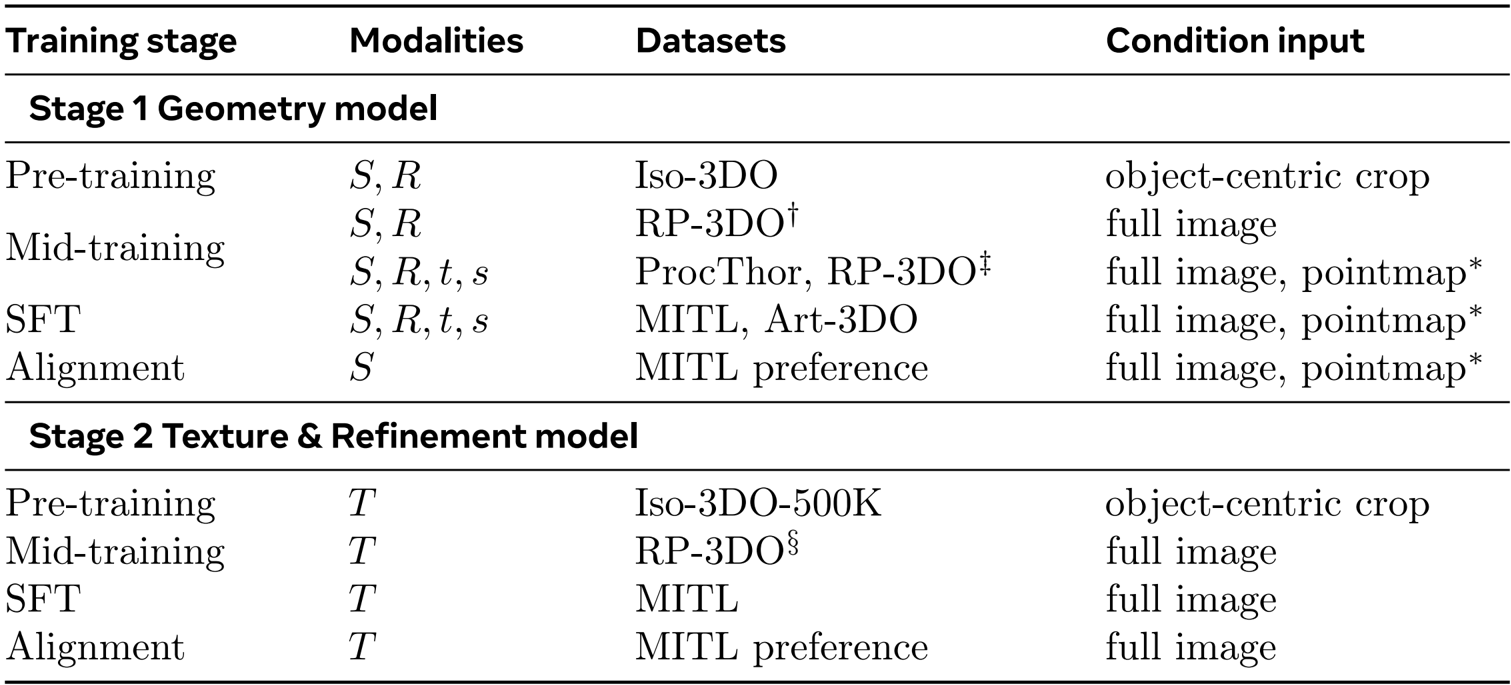
- Author leverages a multi-stage data pipeline combining synthetic, semi-synthetic, and real-world data to train SAM 3D, progressing from pretraining to post-training with increasing realism and human alignment.
- For pretraining, the author uses Iso-3DO, a dataset of 2.7 million synthetic object meshes from Objaverse-XL and licensed sources, rendered from 24 viewpoints to produce high-resolution images of isolated, centered objects; 2.5 trillion training tokens are used, with strict geometric filtering to remove degenerate or structurally anomalous meshes (e.g., flat surfaces, isolated fragments).
- In mid-training, the author constructs RP-3DO, a semi-synthetic "render-paste" dataset with 61 million samples and 2.8 million unique meshes, generated by compositing textured synthetic objects into natural images using alpha blending; this includes two variants: Flying Occlusions (FO) (55.1M samples with occluder-occludee pairs and visibility constraints) and Object Swap – Annotated (OS-A) (0.4M samples using human-annotated meshes and poses from MITL-3DO for pixel-aligned texture consistency).
- All synthetic data is augmented with randomized lighting during rendering to encourage the model to predict "de-lighted" textures, improving generalization and human preference.
- For post-training, the author introduces a data engine that iteratively collects real-world 3D data via human-in-the-loop annotation: starting from 850,000 object instances across 360,000 images from diverse sources (SA-1B, MetaCLIP, Ego4D, BDD100k, etc.), the pipeline uses a best-of-N (N=8) human preference search over 3D shape and texture candidates generated by a suite of models (retrieval, text-to-3D, image-to-3D).
- The annotation process is divided into three stages: (1) object selection using automated and human-verified masks; (2) 3D model ranking via pairwise comparisons; (3) 3D mesh alignment to a 2.5D point cloud using a custom tool with rotation, translation, and scale controls.
- To address hard cases where models fail, a small subset of the most challenging samples is routed to professional 3D artists, forming the Art-3DO dataset, with failure types categorized (e.g., occlusion, transparency) and clustering used to avoid redundancy.
- The final dataset includes ~3.14 million untextured meshes, ~100K textured meshes, and ~1.23 million layout annotations, collected over 7 million pairwise human preferences, with average annotation times of 10s (stage 1), 80s (stage 2), and 150s (stage 3).
- The model is evaluated on a new benchmark, SA-3DAO, consisting of 1,000 high-fidelity 3D meshes created by artists from real images, covering diverse scenes and object types, including complex, occluded, and culturally specific items, serving as a gold-standard for real-world 3D reconstruction.
Method
The SAM 3D model is designed to convert a single image into a composable 3D scene composed of individual, fully reconstructed objects. The overall framework operates in a two-stage process: first, the Geometry model jointly predicts the coarse shape and layout of objects, and then the Texture & Refinement model enhances the shapes by integrating pictorial cues to produce high-fidelity 3D assets. Unlike prior work that reconstructs isolated objects, SAM 3D predicts the object layout, enabling the creation of coherent multi-object scenes. The architecture is built upon a recent state-of-the-art two-stage latent flow matching framework, with a modular design that allows for independent training and refinement of different components.
The input to the model consists of two pairs of images: a cropped object image and its corresponding binary mask, and the full image with its full image binary mask. These are encoded using DINOv2 to extract features, resulting in four sets of conditioning tokens. Optionally, the model can also condition on a coarse scene point map, which can be obtained from hardware sensors like LiDAR or via monocular depth estimation, enabling integration with other pipelines. The Geometry model, which is responsible for predicting the coarse shape O∈R643, 6D rotation R∈R6, translation t∈R3, and scale s∈R3, employs a 1.2B parameter flow transformer with a Mixture-of-Transformers (MoT) architecture. This architecture models the conditional distribution p(O,R,t,s∣I,M) and uses a structured attention mask to enable information sharing between the shape and layout modalities during the forward pass, which is critical for self-consistency. The MoT design allows for independent training of some modalities while maintaining performance on others, thanks to the shared context provided by the joint self-attention layers.
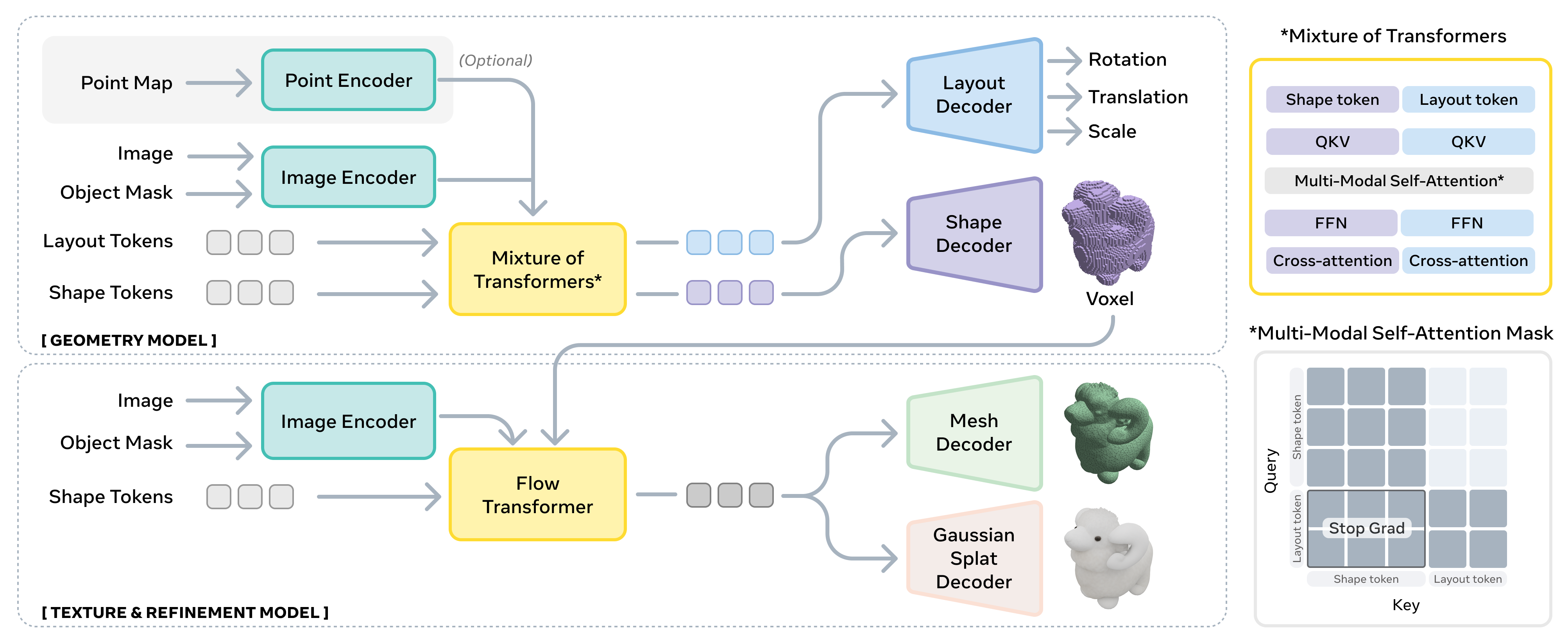 The Geometry model's output, a coarse voxel shape, is then passed to the Texture & Refinement model. This model, which is a 600M parameter sparse latent flow transformer, refines the geometric details and synthesizes object texture by learning the conditional distribution p(S,T∣I,M,O). The latent representations from this model can be decoded into either a mesh or 3D Gaussian splats using a pair of VAE decoders, Dm and Dg, which share the same VAE encoder and structured latent space.
The Geometry model's output, a coarse voxel shape, is then passed to the Texture & Refinement model. This model, which is a 600M parameter sparse latent flow transformer, refines the geometric details and synthesizes object texture by learning the conditional distribution p(S,T∣I,M,O). The latent representations from this model can be decoded into either a mesh or 3D Gaussian splats using a pair of VAE decoders, Dm and Dg, which share the same VAE encoder and structured latent space.
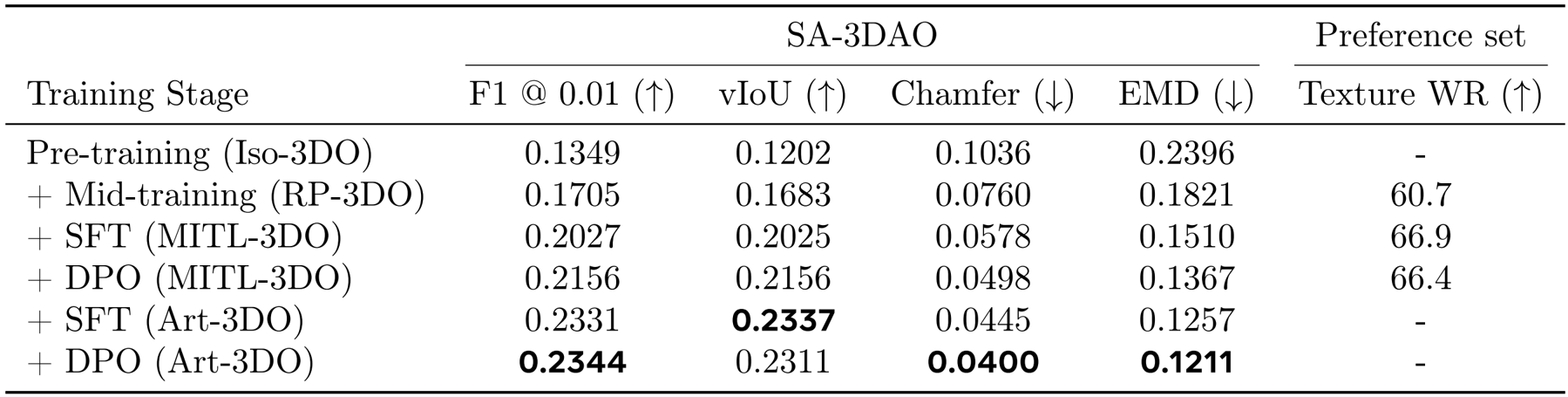
The training of SAM 3D follows a multi-stage pipeline that progresses from synthetic pretraining to natural post-training, adapting the playbook from large language models and robotics. The process begins with synthetic pretraining to build foundational capabilities like shape generation. This is followed by mid-training, which imparts general skills such as occlusion robustness and mask-following. The final stage is post-training, which aligns the model to real data and human-preferred behaviors through a data flywheel. This alignment involves supervised fine-tuning (SFT) and direct preference optimization (DPO). The training stages are detailed in a table, showing the progression from synthetic data (Iso-3DO) to real-world data (MITL, Art-3DO) and the use of preference data for alignment.
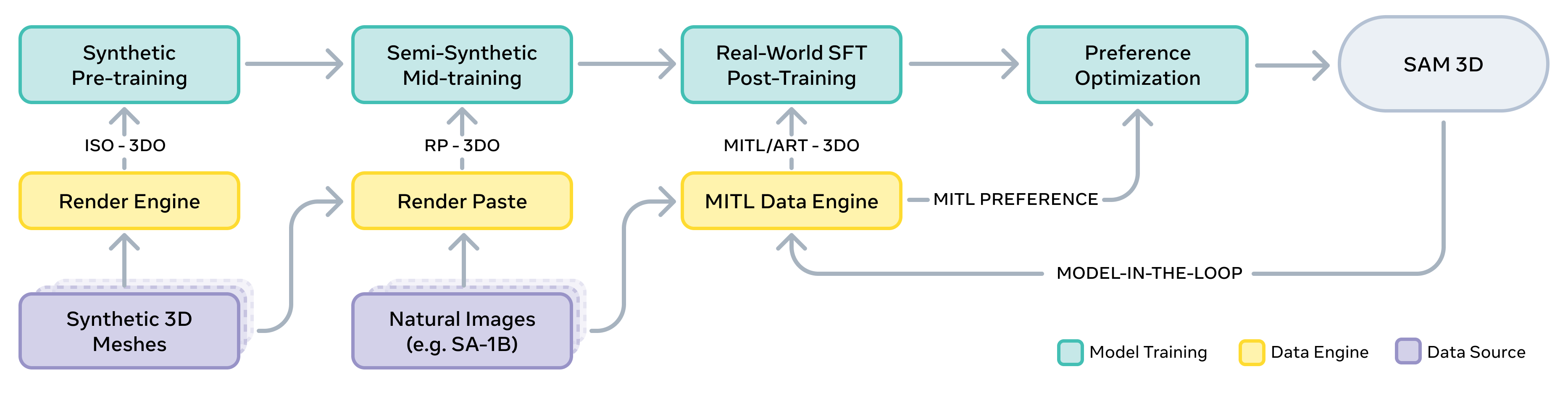 The core alignment algorithm, as shown in the figure, is an online process that iteratively improves the model. In each iteration, the current model is amplified using an ensemble and best-of-N search to generate a set of candidate demonstrations. Human annotators then rank these candidates, selecting the best one and rejecting the others. The collected data, filtered by a quality threshold, is used to train a new model via SFT and DPO. This creates a virtuous cycle where the model's performance improves over time, and the data generation process becomes a byproduct of the alignment.
The core alignment algorithm, as shown in the figure, is an online process that iteratively improves the model. In each iteration, the current model is amplified using an ensemble and best-of-N search to generate a set of candidate demonstrations. Human annotators then rank these candidates, selecting the best one and rejecting the others. The collected data, filtered by a quality threshold, is used to train a new model via SFT and DPO. This creates a virtuous cycle where the model's performance improves over time, and the data generation process becomes a byproduct of the alignment.
The Geometry model is trained using a conditional rectified flow matching objective, which jointly generates multiple 3D modalities. The model denoises the 643 voxel shape in the latent space of a coarser 163×8 representation and performs denoising directly in the parameter space for layout. Modality-specific input and output projection layers map the shape and layout parameters into a shared feature space of dimension 1024. The Texture & Refinement model is trained with a similar flow-matching objective, using SLAT features. For preference alignment, the model uses DPO, which is adapted to flow matching by comparing the predicted velocities of preferred and less preferred outputs. The final step in the training pipeline is model distillation, which reduces the number of function evaluations (NFE) required during inference from 25 to 4. This is achieved by fine-tuning a fully trained model with a shortcut objective that combines flow-matching and self-consistency targets, allowing the model to switch between the original flow matching inference and a faster shortcut mode.
Experiment
- Conducted comprehensive experiments on SA-3DAO, Aria Digital Twin (ADT), LVIS, and a custom human preference set to evaluate 3D layout, shape, texture, and scene reconstruction.
- SAM 3D significantly outperforms both pipeline methods (e.g., Trellis + Megapose, HY3D-2.0 + FoundationPose) and joint generative models (e.g., MIDI) on 3D layout metrics, achieving 0.4254 3D IoU and 0.7232 ADD-S @ 0.1 on SA-3DAO, and 0.4970 3D IoU and 0.7673 ADD-S @ 0.1 on ADT.
- On real-world inputs like SA-3DAO and ADT, SAM 3D achieves a 77% ADD-S @ 0.1, demonstrating a major leap over prior methods that rely on sample-then-optimize approaches.
- Human preference studies show SAM 3D is preferred over SOTA by up to 6:1 in scene reconstruction and 5:1 in shape quality, especially under occlusion and clutter.
- Test-time optimization via render-and-compare further improves SAM 3D’s layout performance on ADT, increasing 3D IoU from 0.4837 to 0.5258 and 2D mask IoU from 0.5143 to 0.6487.
- Ablation studies confirm that multi-stage training, post-training data, and DPO alignment are critical for real-world performance, with reward-model-guided best-of-N search improving annotation yield from 0% to 86.8% on challenging categories like food.
The table outlines the multi-stage training pipeline for SAM 3D, detailing the progression from pre-training to alignment for both the geometry and texture refinement models. The geometry model undergoes pre-training on Iso-3DO with object-centric crops, followed by mid-training on RP-3DO and ProcThor using full images and pointmaps, then SFT on MITL and Art-3DO, and finally alignment on MITL preference data. The texture refinement model follows a similar structure but uses different datasets and condition inputs, starting with pre-training on Iso-3DO-500K and mid-training on RP-3DO, with SFT and alignment on MITL data. This staged approach enables the model to progressively learn from synthetic to real-world data, incorporating both geometric and textural information to improve 3D reconstruction quality.
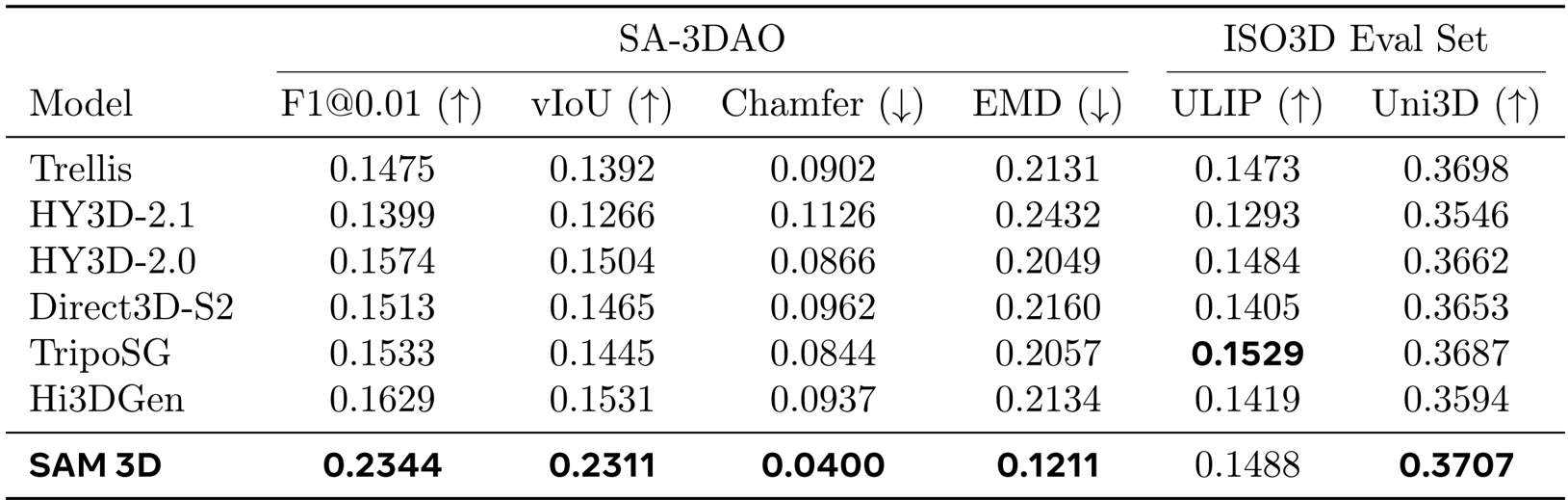
Authors compare SAM 3D with prior state-of-the-art methods on shape quality, showing that SAM 3D significantly outperforms all baselines on the SA-3DAO dataset, achieving the highest scores across all metrics including F1@0.01, vIoU, Chamfer distance, and EMD. On the ISO3D evaluation set, SAM 3D also achieves the best performance in ULIP and Uni3D similarity, demonstrating its strong generalization to real-world inputs and superior shape quality compared to existing methods.
Authors compare SAM 3D with existing pipeline and joint methods on SA-3DAO and Aria Digital Twin datasets, showing that SAM 3D significantly outperforms all pipeline approaches and the joint model MIDI in all evaluated metrics. The results demonstrate that SAM 3D achieves the highest 3D IoU, lowest ICP-Rot and ADD-S, and best ADD-S @ 0.1 scores, highlighting its superior capability in jointly generating accurate 3D shapes and layouts.

The table demonstrates the incremental improvements in 3D shape and texture quality as each training stage is added to SAM 3D. Starting from pre-training on Iso-3DO, the model shows steady gains in F1 score, voxel IoU, and Chamfer distance, with the final DPO stage on Art-3DO achieving the best performance on SA-3DAO metrics and a texture win rate of 66.4% on the preference set.