Command Palette
Search for a command to run...
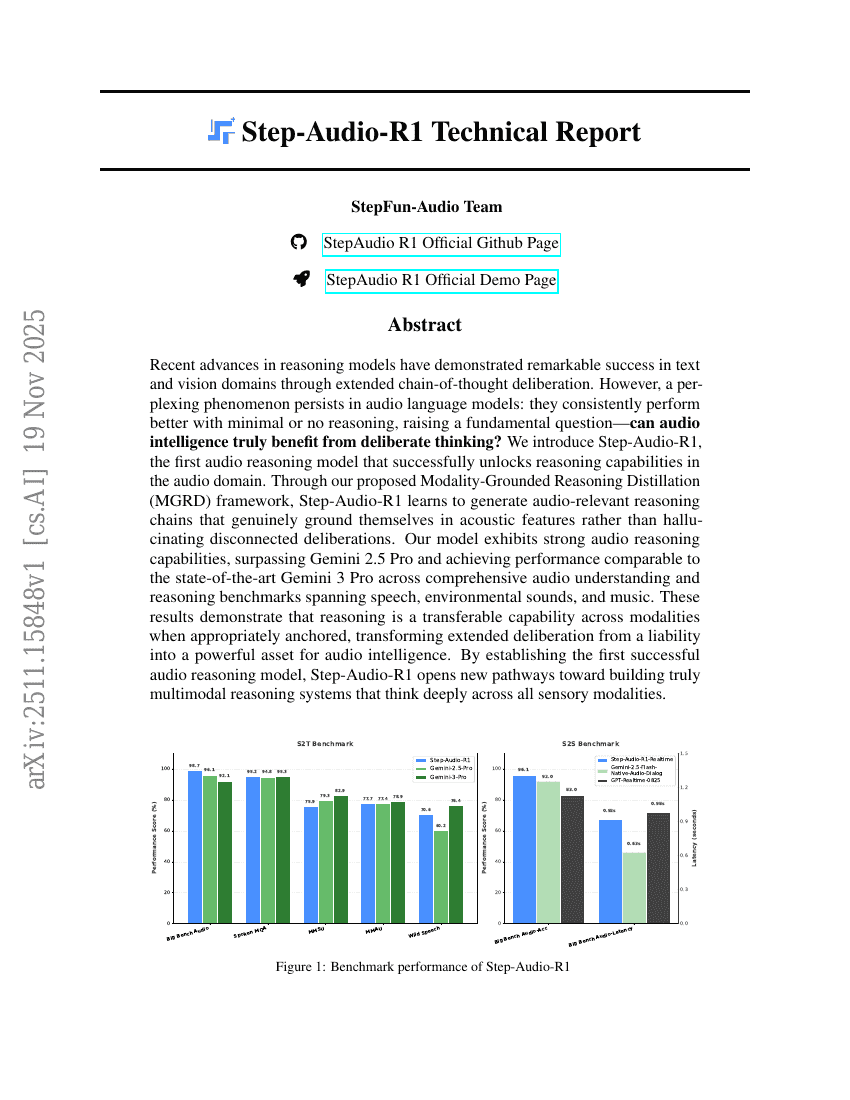
초록
최근 리뷰잉 모델의 발전은 연쇄적 사고(Chain-of-Thought)를 통해 텍스트 및 비전 분야에서 놀라운 성과를 거두었다. 그러나 음성 언어 모델에서는 여전히 의문스러운 현상이 지속되고 있다. 즉, 최소한의 사고 또는 전혀 사고 없이도 오히려 더 우수한 성능을 보이는 것이다. 이로 인해 근본적인 질문이 제기된다. 음성 지능은 진정으로 사고적 사고를 통해 혜택을 얻을 수 있을까? 우리는 음성 분야에서 사고 능력을 성공적으로 구현한 최초의 음성 사고 모델인 Step-Audio-R1을 소개한다. 제안한 모달리티 기반 사고 정제(Modality-Grounded Reasoning Distillation, MGRD) 프레임워크를 통해 Step-Audio-R1은 음성 특징에 실제로 기반한 실제적인 사고 체인을 생성하는 능력을 습득한다. 이는 고립된 추론을 환상적으로 생성하는 것이 아니라, 음향 특성에 부합하는 의미 있는 사고 흐름을 형성하는 것을 의미한다. 본 모델은 강력한 음성 사고 능력을 보이며, Gemini 2.5 Pro를 능가하고, 최신 기술 수준의 Gemini 3 Pro와 비슷한 성능을 다양한 음성 이해 및 사고 벤치마크(화성, 환경음, 음악 포함)에서 달성했다. 이러한 결과는 적절히 모달리티에 기반을 두었을 때 사고 능력이 다양한 모달리티 간에 전이 가능함을 보여주며, 연장된 사고가 음성 지능의 부담이 아니라 강력한 자산으로 전환될 수 있음을 입증한다. Step-Audio-R1은 최초로 성공적인 음성 사고 모델을 구축함으로써, 모든 감각 모달리티를 아우르는 깊이 있는 사고를 가능하게 하는 진정한 다모달 사고 시스템 구축을 위한 새로운 길을 열었다.