Command Palette
Search for a command to run...
Yicheng He Chengsong Huang Zongxia Li Jiaxin Huang Yonghui Yang
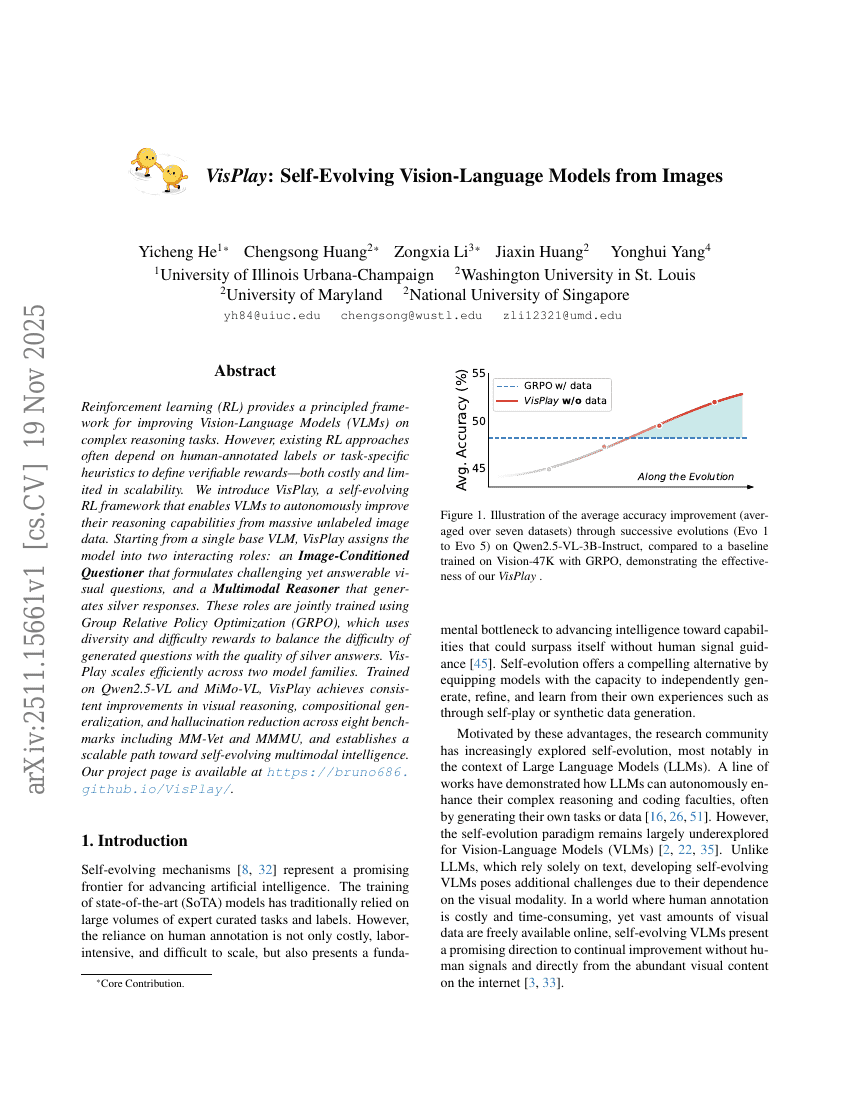
초록
강화학습(RL)은 복잡한 추론 과제에서 시각-언어 모델(VLM)을 개선하기 위한 체계적인 프레임워크를 제공한다. 그러나 기존의 RL 접근 방식은 검증 가능한 보상(reward)을 정의하기 위해 인간의 레이블 또는 과제에 특화된 히우리스틱을 종종 의존하며, 이는 비용이 많이 들고 확장하기 어렵다. 본 연구에서는 대량의 레이블이 없는 이미지 데이터를 활용해 VLM이 자율적으로 추론 능력을 향상시킬 수 있는 자기진화형 RL 프레임워크인 VisPlay을 제안한다. VisPlay는 단일 기반 VLM에서 출발하여 모델을 두 가지 상호작용하는 역할로 분할한다: 시각 정보에 조건부로 도전적이지만 해답이 가능한 시각적 질문을 생성하는 '이미지 조건부 질문자(Image-Conditioned Questioner)'와, 은색(은은한) 응답(silver responses)을 생성하는 '다중모달 추론기(Multimodal Reasoner)'이다. 이 두 역할은 다수의 정책을 함께 최적화하는 그룹 상대적 정책 최적화(Group Relative Policy Optimization, GRPO)를 통해 공동 학습되며, 다양성과 난이도 보상을 포함하여 생성된 질문의 복잡성과 은색 응답의 품질 간의 균형을 유지한다. VisPlay는 두 가지 모델 패밀리에 대해 효율적으로 확장 가능하다. Qwen2.5-VL과 MiMo-VL에서 훈련된 결과, VisPlay는 MM-Vet, MMMU를 포함한 8개의 벤치마크에서 시각적 추론 능력, 복합적 일반화 성능, 환각 현상 감소 측면에서 일관된 성능 향상을 보였다. 이는 자기진화형 다중모달 지능으로 나아가는 확장 가능한 길을 제시한다. 프로젝트 페이지는 다음 링크에서 확인할 수 있다: https://bruno686.github.io/VisPlay/