Command Palette
Search for a command to run...
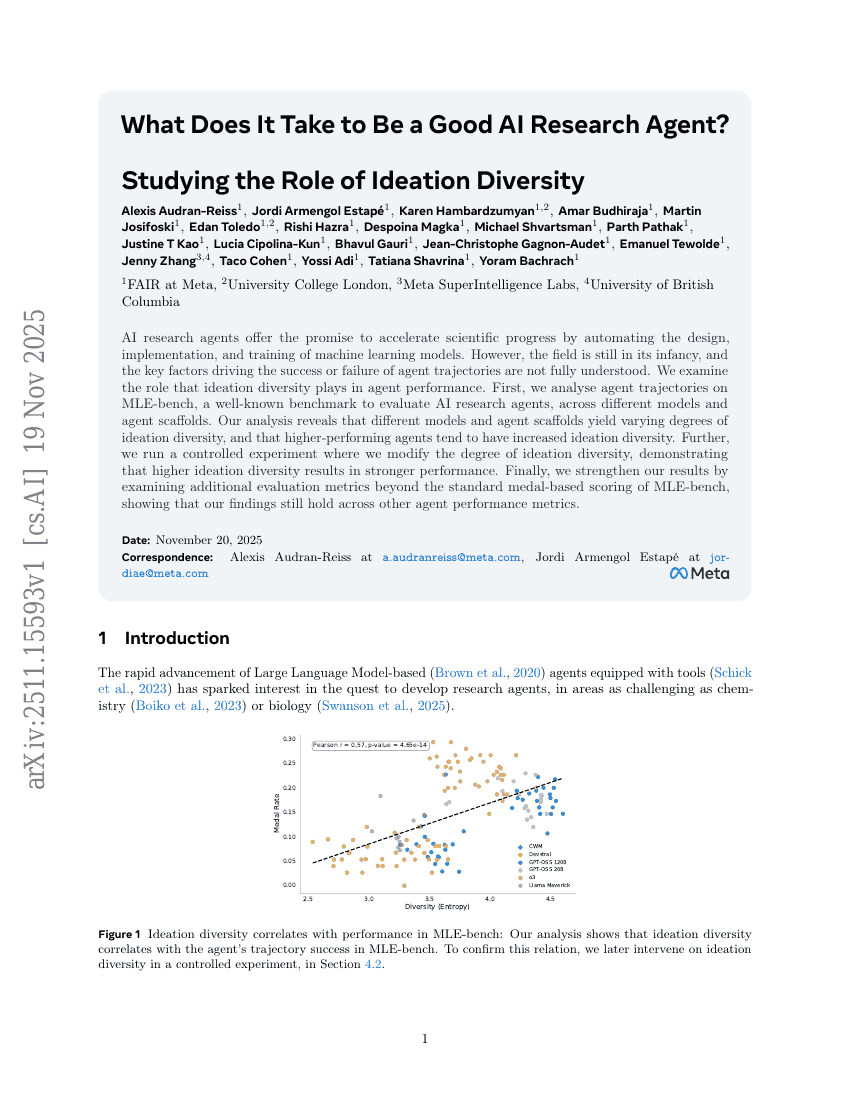
초록
AI 연구 에이전트는 머신러닝 모델의 설계, 구현 및 훈련 과정을 자동화함으로써 과학적 진보를 가속화할 잠재력을 지닌다. 그러나 이 분야는 여전히 초기 단계에 있으며, 에이전트의 성공 또는 실패를 결정짓는 핵심 요인들은 완전히 이해되지 않았다. 본 연구에서는 아이디어 다양성(ideation diversity)이 에이전트 성능에 미치는 역할을 탐구한다. 먼저, AI 연구 에이전트를 평가하기 위해 널리 사용되는 MLE-bench 벤치마크에서 다양한 모델과 에이전트 스카폴드(agent scaffolds)에 대한 에이전트 경로를 분석한다. 분석 결과, 서로 다른 모델과 에이전트 스카폴드는 각기 다른 수준의 아이디어 다양성을 생성하며, 성능이 뛰어난 에이전트일수록 더 높은 아이디어 다양성을 보이는 경향이 있음을 확인했다. 추가적으로, 아이디어 다양성의 수준을 조절하는 통제 실험을 수행한 결과, 더 높은 아이디어 다양성이 더 강한 성능을 초래함을 입증하였다. 마지막으로, MLE-bench의 표준 메달 기반 평가 외에 추가적인 평가 지표를 분석함으로써 결과의 타당성을 강화하였으며, 다양한 에이전트 성능 지표에서도 본 연구의 발견이 일관되게 유지됨을 확인하였다.