Command Palette
Search for a command to run...
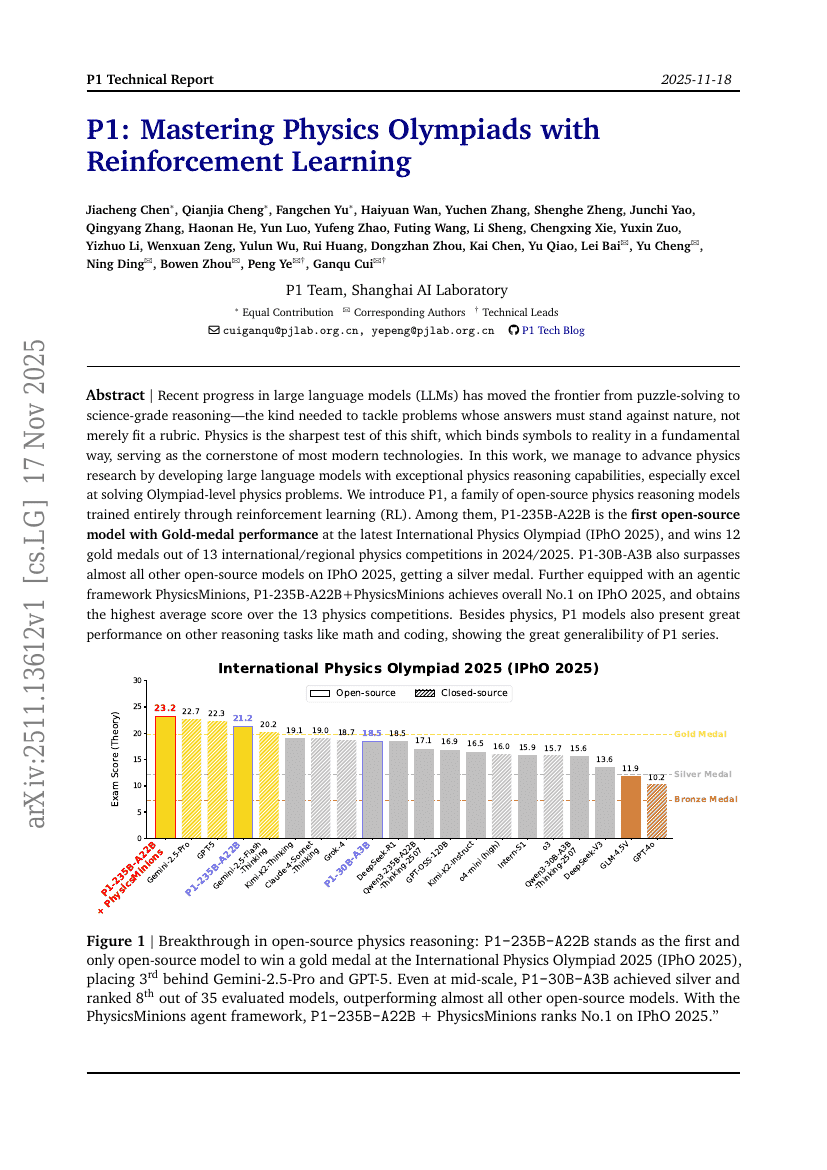
초록
최근 대규모 언어 모델(LLM)의 발전은 퍼즐 해결을 넘어서, 자연의 법칙에 도전할 수 있어야 하는 과학 수준의 추론으로 경계를 확장하고 있다. 이러한 추론은 단순히 평가 기준에 부합하는 것을 넘어서, 실제 자연과 일치해야 하는 진정한 의미의 사고 능력을 요구한다. 물리학은 이러한 전환의 가장 엄격한 시험대이며, 기호와 현실을 근본적으로 연결하는 분야로서 현대 기술의 대부분의 기초를 형성한다. 본 연구에서는 물리학 문제 해결 능력이 뛰어난 대규모 언어 모델을 개발함으로써 물리학 연구를 촉진하였다. 특히 올림피아드 수준의 물리 문제를 매우 잘 풀 수 있는 모델을 구현하였다. 우리는 전적으로 강화 학습(RL)을 통해 훈련된 오픈소스 물리 추론 모델인 P1 시리즈를 소개한다. 이 중 P1-235B-A22B는 최신 국제물리올림피아드(IPhO 2025)에서 금메달 성적을 달성한 최초의 오픈소스 모델이며, 2024~2025년 기준 13개의 국제·지역 물리 경시대회에서 12개에서 금메달을 획득했다. 또한 P1-30B-A3B는 IPhO 2025에서 거의 모든 다른 오픈소스 모델을 앞지르며 은메달을 수상했다. 더불어 에이전트 기반 프레임워크인 PhysicsMinions를 결합한 P1-235B-A22B+PhysicsMinions는 IPhO 2025에서 종합 1위를 기록하며, 13개의 물리 경시대회에서 평균 점수도 최고를 달성했다. 물리학 외에도 P1 시리즈는 수학 및 코딩과 같은 다른 추론 과제에서도 뛰어난 성능을 보이며, P1 시리즈의 뛰어난 일반화 능력을 입증한다.