Command Palette
Search for a command to run...
Shulin Liu Dong Du Tao Yang Yang Li Boyu Qiu
초록
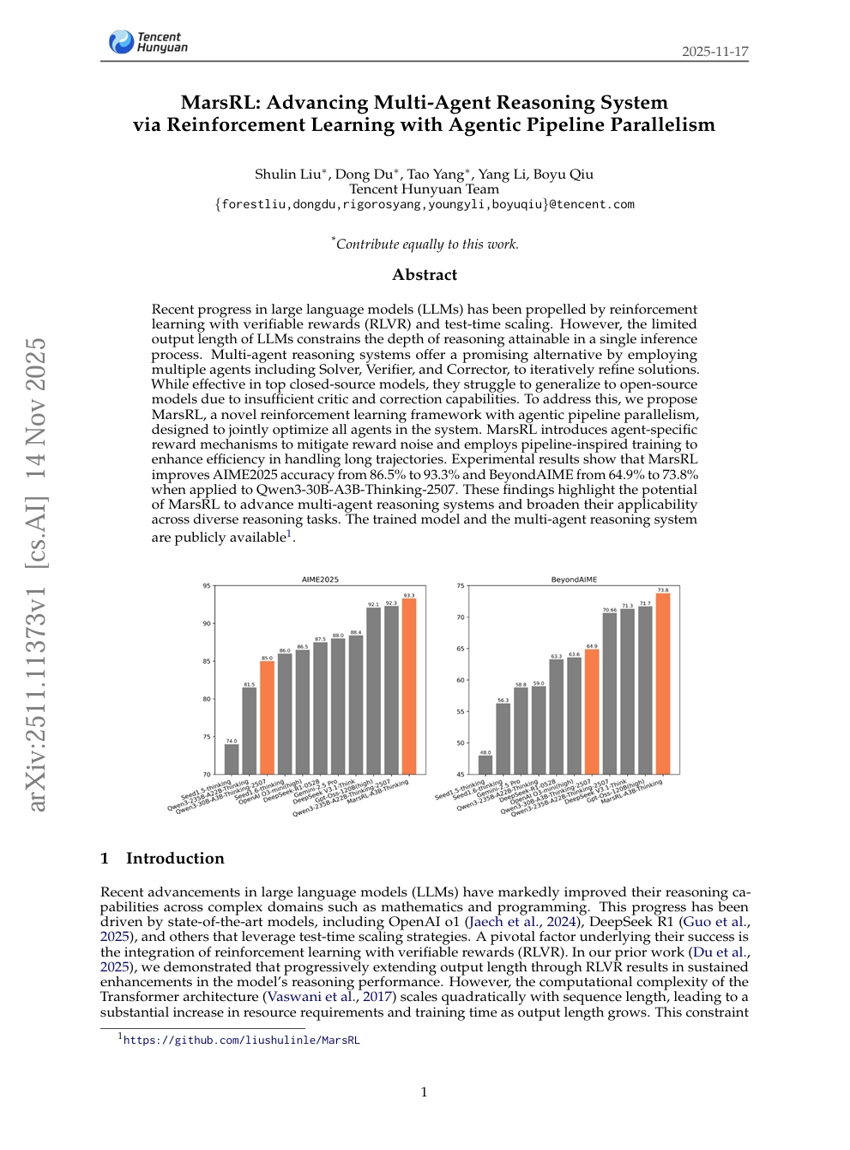
최근 대규모 언어 모델(LLM)의 발전은 검증 가능한 보상과 함께 강화학습(RLVR) 및 테스트 시 스케일링 기법에 의해 주도되고 있다. 그러나 LLM의 출력 길이 제한으로 인해 단일 추론 과정 내에서 달성 가능한 추론의 깊이가 제한된다. 다중 에이전트 추론 시스템은 솔버(Solver), 검증자(Verifier), 수정자(Corrector) 등 여러 에이전트를 활용하여 해결책을 반복적으로 개선함으로써 이 문제에 대한 유망한 대안을 제시한다. 기존의 폐쇄형 모델(Gemini 2.5 Pro 등)에서는 효과적이지만, 비판 및 수정 능력이 부족한 개방형 모델에서는 일반화에 어려움을 겪는다. 이를 해결하기 위해 우리는 에이전트 기반 파이프라인 병렬 처리를 갖춘 새로운 강화학습 프레임워크인 MarsRL을 제안한다. MarsRL은 시스템 내 모든 에이전트를 공동 최적화하도록 설계되었으며, 에이전트별 보상 메커니즘을 도입하여 보상 노이즈를 완화하고, 파이프라인 기반의 학습 방식을 활용해 긴 추적 경로 처리 효율성을 높였다. Qwen3-30B-A3B-Thinking-2507에 적용한 결과, MarsRL은 AIME2025 정확도를 86.5%에서 93.3%로 향상시키며, BeyondAIME의 정확도 역시 64.9%에서 73.8%로 개선되었으며, 이는 Qwen3-235B-A22B-Thinking-2507를 초과하는 성능을 달성했다. 이러한 결과는 MarsRL이 다중 에이전트 추론 시스템의 성능을 향상시키고 다양한 추론 과제에 걸쳐 보다 넓은 적용 가능성을 제공할 수 있음을 시사한다.