Command Palette
Search for a command to run...
Haotong Lin Sili Chen Junhao Liew Donny Y. Chen Zhenyu Li Guang Shi Jiashi Feng Bingyi Kang
초록
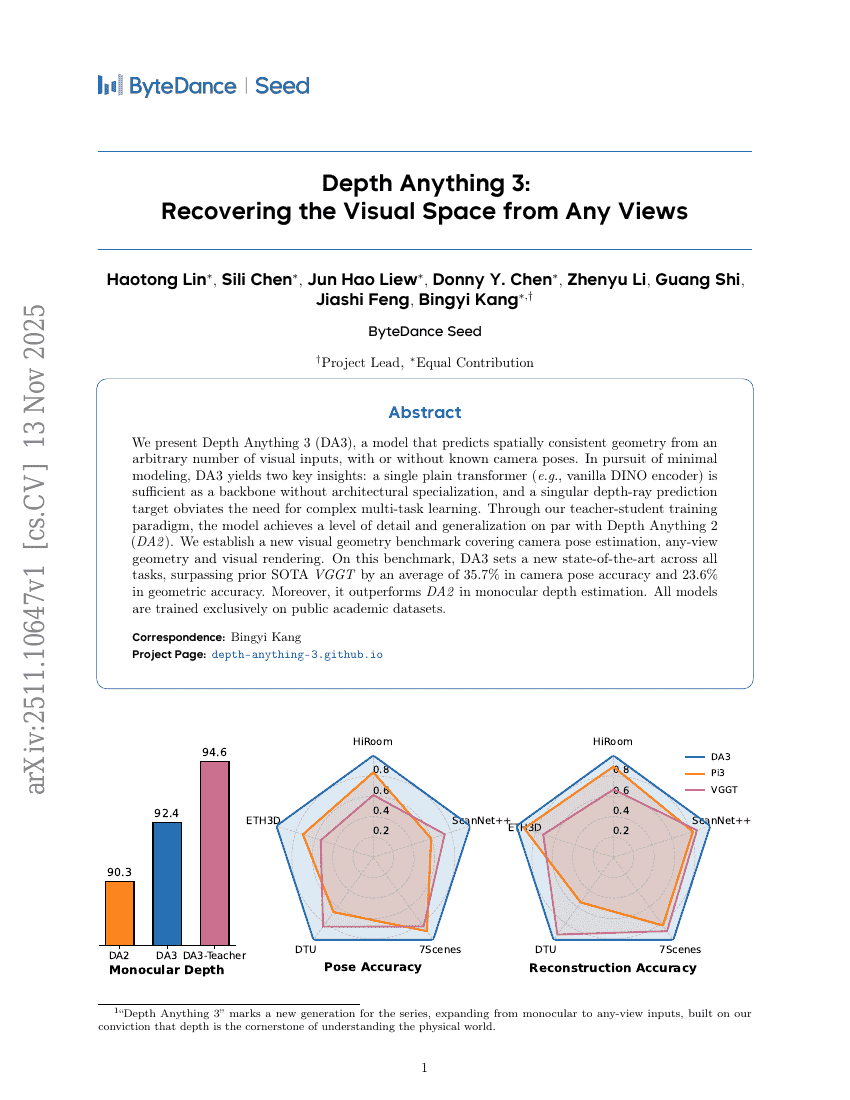
우리는 임의의 수의 시각 입력(또는 알려진 카메라 자세가 없는 경우도 포함)으로부터 공간적으로 일관된 기하 구조를 예측할 수 있는 모델인 Depth Anything 3(DA3)을 제안한다. 최소한의 모델링을 추구함에 있어 DA3는 두 가지 핵심 통찰을 도출한다. 첫째, 특별한 아키텍처 설계 없이도 단일 일반형 트랜스포머(예: 순수한 DINO 인코더)만으로도 충분한 백본으로 기능할 수 있으며, 둘째, 단일한 깊이-광선 예측 목표만으로도 복잡한 다중 작업 학습의 필요성을 제거할 수 있다. 본 연구에서 제안하는 교사-학생 학습 프레임워크를 통해 DA3는 Depth Anything 2(DA2)와 동등한 수준의 세부 정보 표현력과 일반화 성능을 달성하였다. 또한 카메라 자세 추정, 임의의 시점 기하 구조 추출, 시각적 렌더링을 아우르는 새로운 시각 기하 기준 평가 벤치마크를 구축하였다. 이 벤치마크에서 DA3는 모든 작업에서 새로운 최고 성능을 기록하였으며, 기존 최고 성능 모델인 VGGT보다 카메라 자세 정확도에서 평균 44.3%, 기하 정확도에서 평균 25.1% 우수한 성능을 보였다. 더불어 단안 깊이 추정에서도 DA2를 능가하는 성능을 나타냈다. 모든 모델은 공개된 학술 데이터셋에만 기반하여 학습되었다.