Command Palette
Search for a command to run...
Tianzhu Ye Li Dong Zewen Chi Xun Wu Shaohan Huang Furu Wei
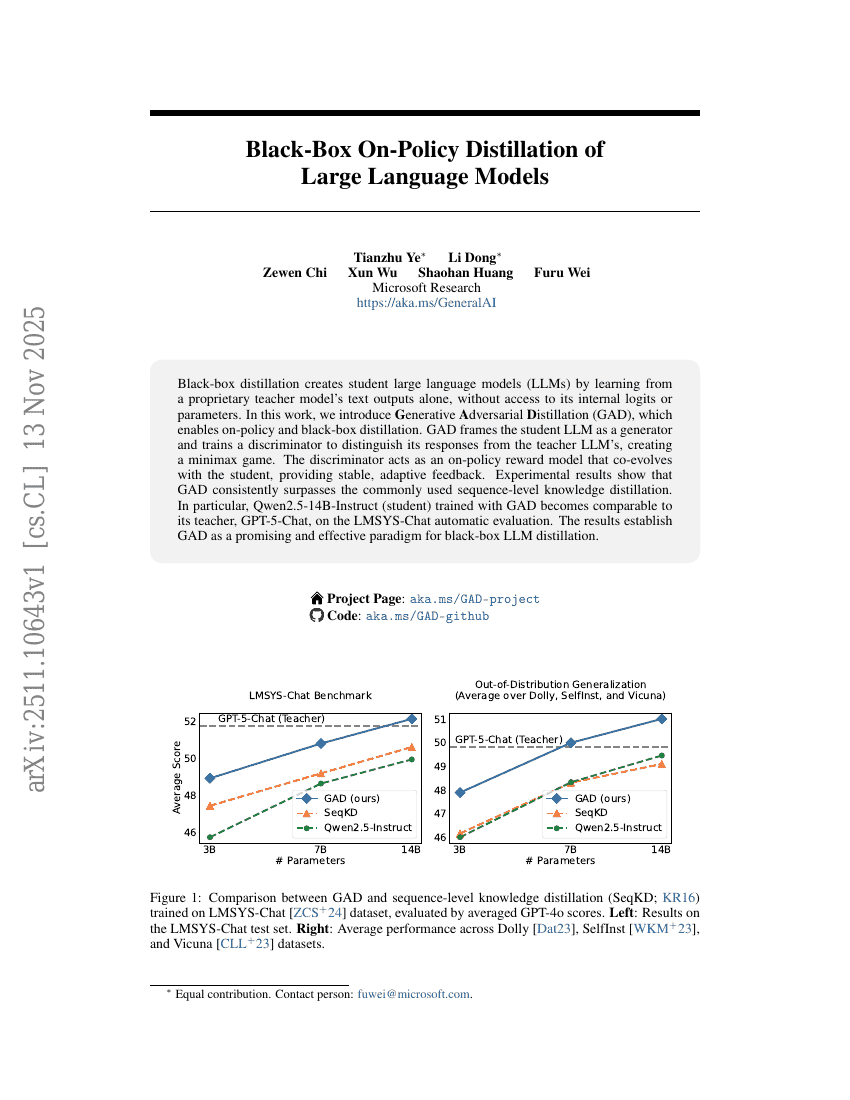
초록
블랙박스 디스틸레이션은 내부 로짓이나 파라미터에 접근하지 않고, 특허받은 테이처 모델의 텍스트 출력만을 통해 학생용 대규모 언어 모델(Large Language Models, LLMs)을 생성한다. 본 연구에서는 온폴리시(on-policy) 및 블랙박스 디스틸레이션을 가능하게 하는 생성적 적대적 디스틸레이션(Generative Adversarial Distillation, GAD)을 제안한다. GAD는 학생 LLM을 생성기(generator)로 간주하고, 학생의 응답과 테이처 LLM의 응답을 구분할 수 있도록 판별기(discriminator)를 학습시켜 미니맥스 게임(minimax game)을 구성한다. 이 판별기는 학생과 공진화하는 온폴리시 보상 모델로 작용하며, 안정적이고 적응형 피드백을 제공한다. 실험 결과, GAD는 일반적으로 사용되는 시퀀스 수준의 지식 디스틸레이션을 일관되게 상회함을 보였다. 특히, GAD로 훈련된 Qwen2.5-14B-Instruct(학생 모델)는 LMSYS-Chat 자동 평가에서 그 테이처 모델인 GPT-5-Chat과 유사한 성능을 달성하였다. 이러한 결과는 GAD가 블랙박스 LLM 디스틸레이션 분야에서 유망하고 효과적인 새로운 패러다임임을 입증한다.