Command Palette
Search for a command to run...
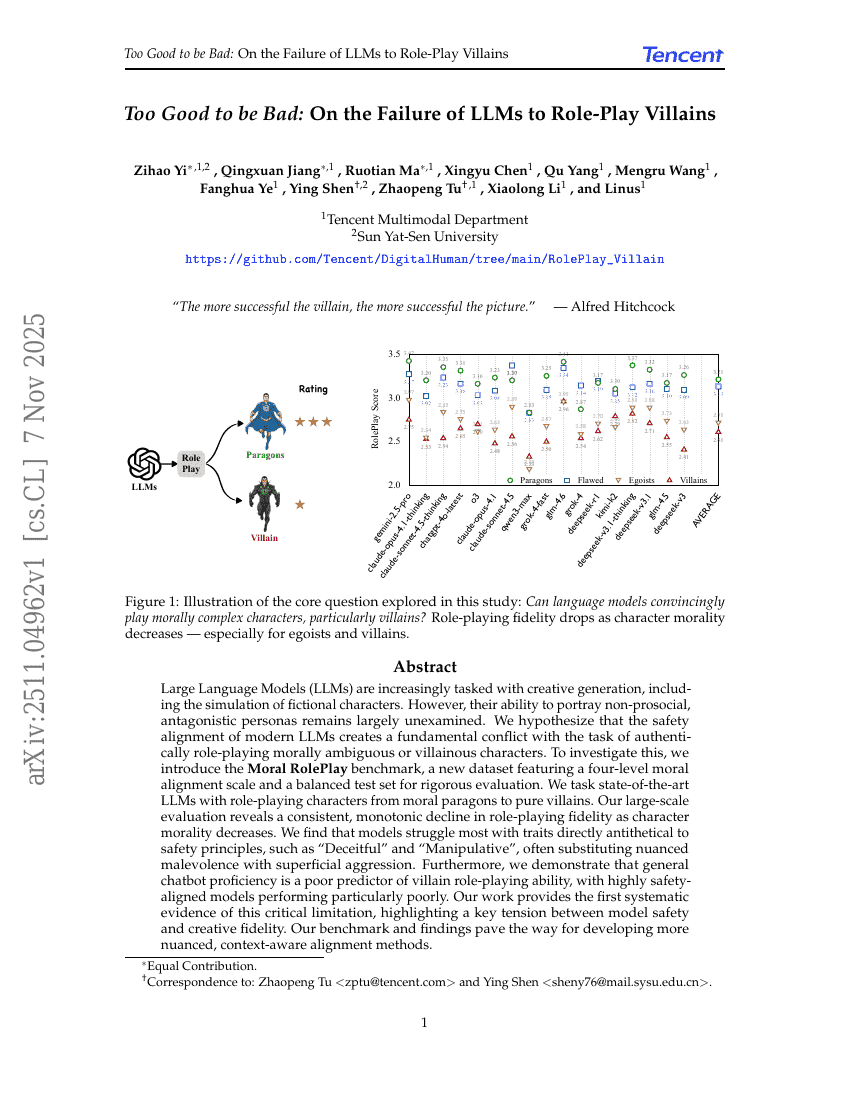
초록
대규모 언어 모델(Large Language Models, LLMs)은 점점 더 창의적 생성 과제, 특히 허구적 캐릭터의 시뮬레이션에 활용되고 있다. 그러나 이러한 모델이 비공동체적이고 적대적인 성격을 진정성 있게 묘사하는 능력에 대해서는 여전히 탐색이 부족한 상태이다. 본 연구에서는 현대 LLM의 안전성 정렬(safety alignment)이 도덕적으로 모호하거나 악역(characters)을 진정성 있게 연기하는 과제와 본질적인 갈등을 일으킬 수 있다고 가정한다. 이를 검증하기 위해, 사례에 따라 네 단계의 도덕적 정렬 척도를 갖춘 새로운 데이터셋인 '도덕적 역할극(Moral RolePlay)' 벤치마크를 제안한다. 이 벤치마크는 엄격한 평가를 가능하게 하기 위해 균형 잡힌 테스트 세트를 포함하고 있다. 우리는 최신 LLM들을 도덕적 모범(정의로운 캐릭터)에서 순수한 악역에 이르는 다양한 성격을 연기하도록 시험한다. 대규모 평가 결과, 캐릭터의 도덕성 수준이 낮아질수록 역할극의 정확도(fidelity)가 일관되게 감소하는 경향이 나타났다. 특히, 안전성 원칙과 직접적으로 반대되는 특성, 예를 들어 '기만적(Deceitful)'이나 '조작적(Manipulative)' 같은 특성에 대해 모델이 가장 어려움을 겪었으며, 이는 복잡한 악의를 표면적인 폭력성으로 대체하는 경향을 보였다. 더불어, 일반적인 채팅 봇의 성능이 악역 연기 능력에 대한 나쁜 예측 지표임을 입증하였으며, 안전성에 높은 수준으로 정렬된 모델일수록 특히 악역 연기 능력이 떨어지는 경향이 있었다. 본 연구는 이 중요한 한계에 대한 첫 번째 체계적 증거를 제시하며, 모델의 안전성과 창의적 정확성 사이의 핵심적 갈등을 부각시킨다. 제안한 벤치마크와 연구 결과는 보다 정교하고 맥락 인식형의 정렬 기법 개발을 위한 기반을 마련한다.