Command Palette
Search for a command to run...
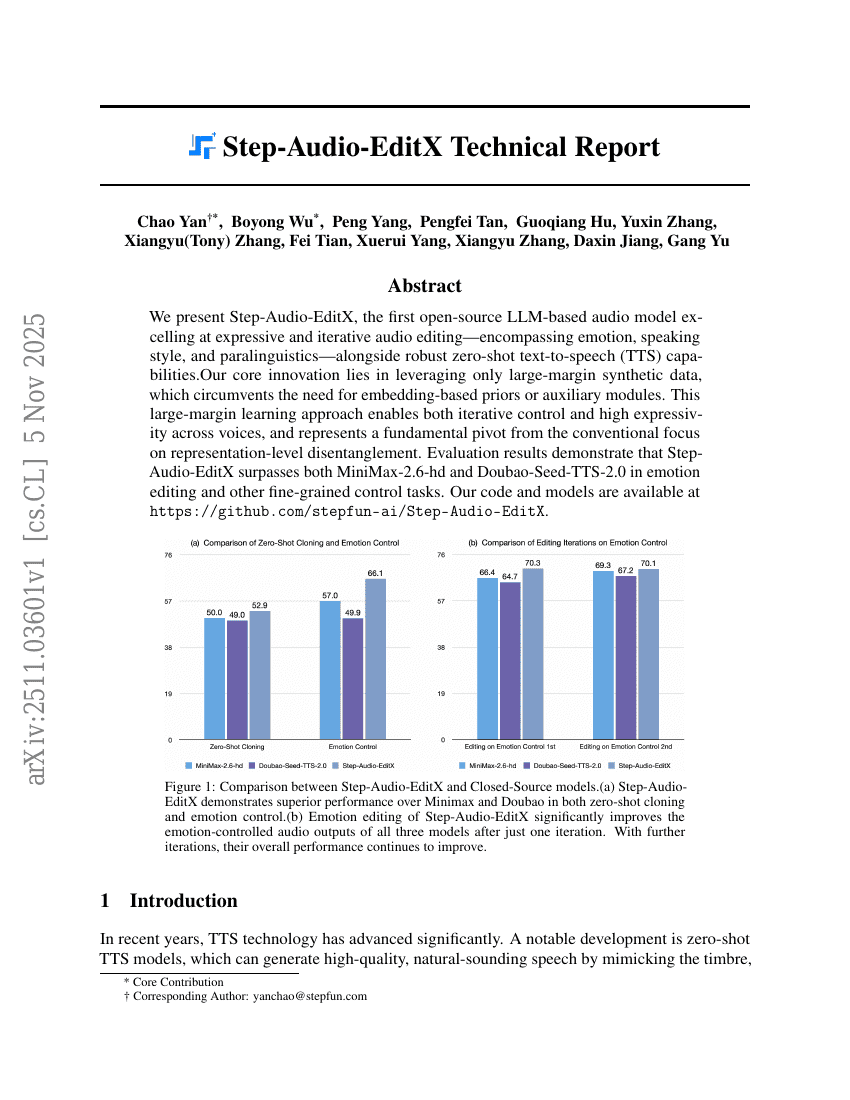
초록
우리는 감정, 발화 스타일, 부언적 특성 등 다양한 요소를 포함한 표현력 높고 반복적인 음성 편집 능력과 견고한 제로샷 텍스트-to-음성(TTS) 기능을 갖춘, 처음으로 공개된 LLM 기반 음성 모델인 Step-Audio-EditX를 제안한다. 본 연구의 핵심 혁신은 임베딩 기반 사전 지식이나 보조 모듈 없이도 대규모 마진을 가진 합성 데이터만을 활용하는 점이다. 이 대규모 마진 학습 방식은 음성의 표현력과 반복적 제어 능력을 동시에 달성하며, 기존의 표현 수준에서의 분리(디센트랑글레이션)에 초점을 맞추는 전통적 접근 방식에서 근본적인 전환을 이룬다. 평가 결과, Step-Audio-EditX는 감정 편집 및 기타 세부 제어 작업에서 MiniMax-2.6-hd와 Doubao-Seed-TTS-2.0를 모두 상회함을 입증하였다.