Command Palette
Search for a command to run...
Bo Liu Chuanyang Jin Seungone Kim Weizhe Yuan Wenting Zhao Ilia Kulikov Xian Li Sainbayar Sukhbaatar Jack Lanchantin Jason Weston
초록
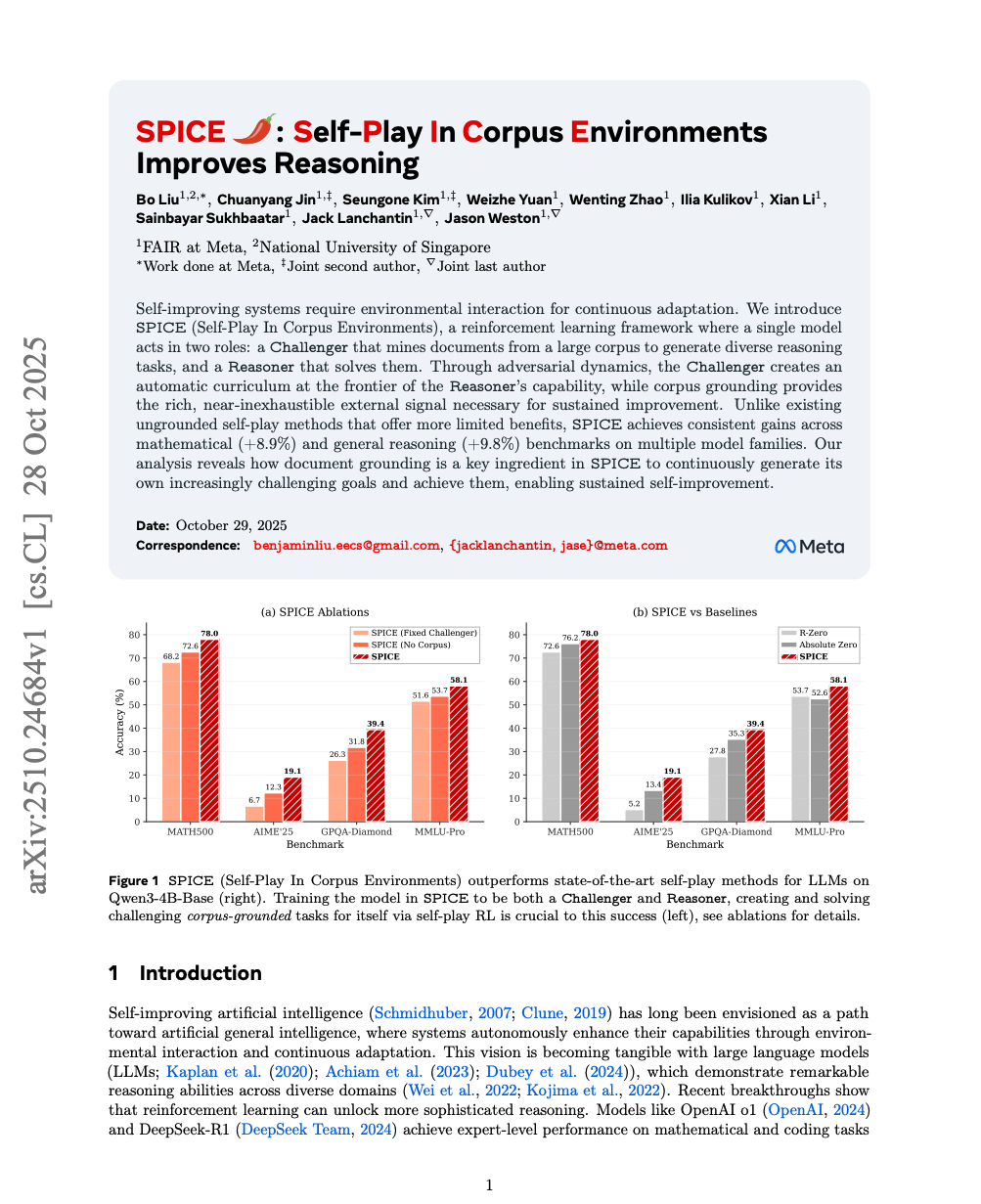
자기 개선 시스템은 지속적인 적응을 위해 환경과의 상호작용이 필요하다. 본 연구에서는 단일 모델이 두 가지 역할을 수행하는 강화학습 프레임워크인 SPICE(Self-Play In Corpus Environments)를 제안한다. 이 모델은 대규모 문헌 코퍼스에서 문서를 탐색하여 다양한 추론 과제를 생성하는 '도전자(Challenger)'와, 그 과제를 해결하는 '추론자(Reasoner)'의 역할을 맡는다. 적대적 동역학을 통해 도전자는 추론자의 능력 한계에 맞춰 자동으로 학습 과정(curriculum)을 생성하고, 코퍼스 기반의 풍부하고 거의 고갈되지 않는 외부 신호를 제공함으로써 지속적인 성능 향상을 가능하게 한다. 기존의 코퍼스 기반 없이 진행되는 자기 대결(self-play) 방법들과 달리, SPICE는 다양한 모델 계열에서 수학적 추론(+8.9%) 및 일반 추론(+9.8%) 벤치마크에서 일관된 성능 향상을 달성한다. 분석 결과, 문서 기반의 지식 제공이 SPICE에서 스스로 점점 더 도전적인 목표를 지속적으로 생성하고 이를 달성함으로써 지속적인 자기 개선을 가능하게 하는 핵심 요소임을 확인하였다.