Command Palette
Search for a command to run...
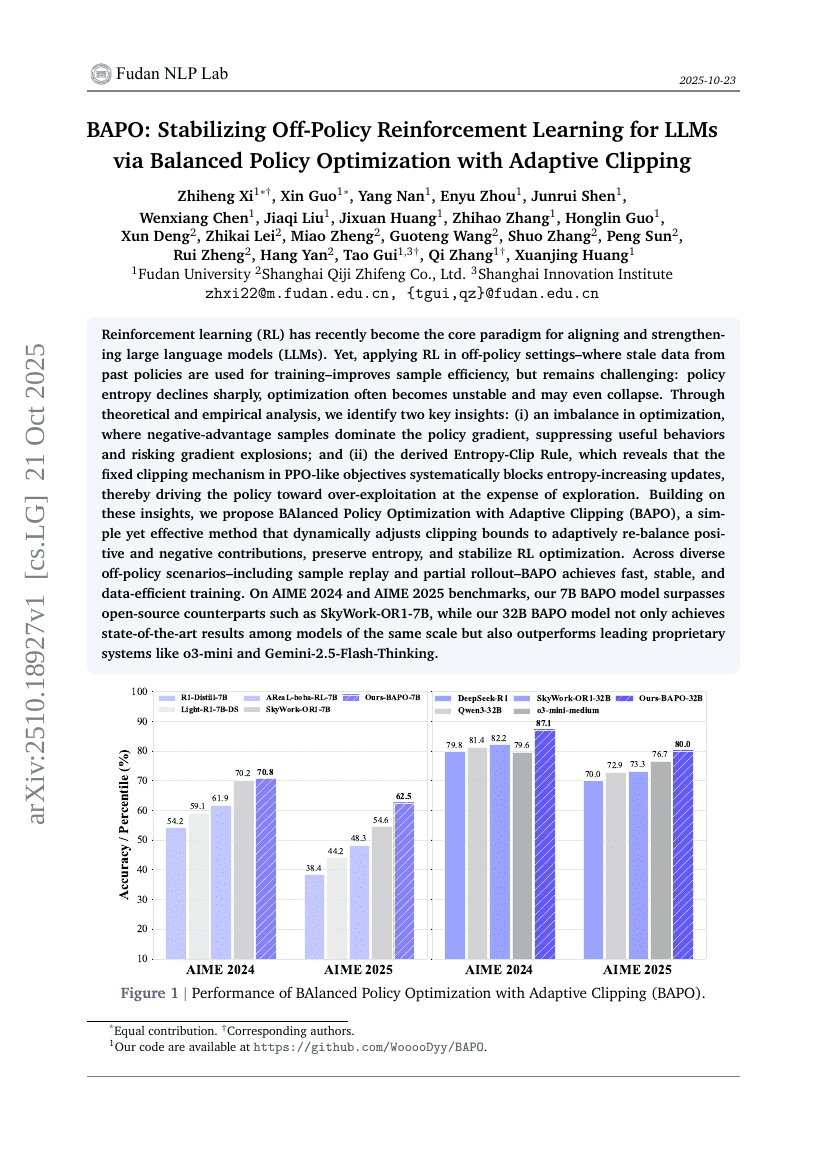
초록
최근 강화학습(RL)은 대규모 언어모델(LLM)의 정렬과 강화를 위한 핵심 패러다임으로 부상하고 있다. 그러나 과거 정책에서 생성된 오래된 데이터를 사용하여 훈련하는 오프-폴리시(off-policy) 환경에서 RL을 적용할 경우, 샘플 효율성이 향상되지만 여전히 도전 과제가 있다. 정책 엔트로피는 급격히 감소하고, 최적화는 불안정해지며 심지어 붕괴될 수 있다. 이에 대해 이론적·실험적 분석을 통해 두 가지 핵심 통찰을 도출하였다. 첫째, 정책 그래디언트에서 음의 보상(advantage)을 가진 샘플이 지배적인 불균형이 발생함으로써 유용한 행동이 억제되고 그래디언트 폭발의 위험이 높아진다. 둘째, 엔트로피-클리핑 규칙(Entropy-Clip Rule)을 도출한 결과, PPO와 유사한 목적함수에서 고정된 클리핑 메커니즘이 엔트로피 증가 업데이트를 체계적으로 차단함으로써, 탐색을 희생하고 과도한 탐사(exploitation)로 정책을 몰아가는 경향이 있음을 밝혀냈다. 이러한 통찰을 바탕으로, 긍정적·음성 기여를 동적으로 재균형화하고 엔트로피를 유지하며 RL 최적화를 안정화하는, 적응형 클리핑을 적용한 단순하면서도 효과적인 방법인 BAlanced Policy Optimization with Adaptive Clipping(BAPO)을 제안한다. 다양한 오프-폴리시 시나리오—예를 들어 샘플 리플레이(sample replay) 및 부분 롤아웃(partial rollout) 등—에서 BAPO는 빠르고 안정적이며 데이터 효율적인 훈련을 달성한다. AIME 2024 및 AIME 2025 벤치마크에서, 7B 규모의 BAPO 모델은 SkyWork-OR1-7B와 같은 오픈소스 모델을 상회하며, 32B 규모의 BAPO 모델은 동급 모델 중 최고 성능을 기록할 뿐만 아니라, o3-mini 및 Gemini-2.5-Flash-Thinking과 같은 선도적인 사적 시스템을도 압도하는 성능을 보였다.