Command Palette
Search for a command to run...
초록
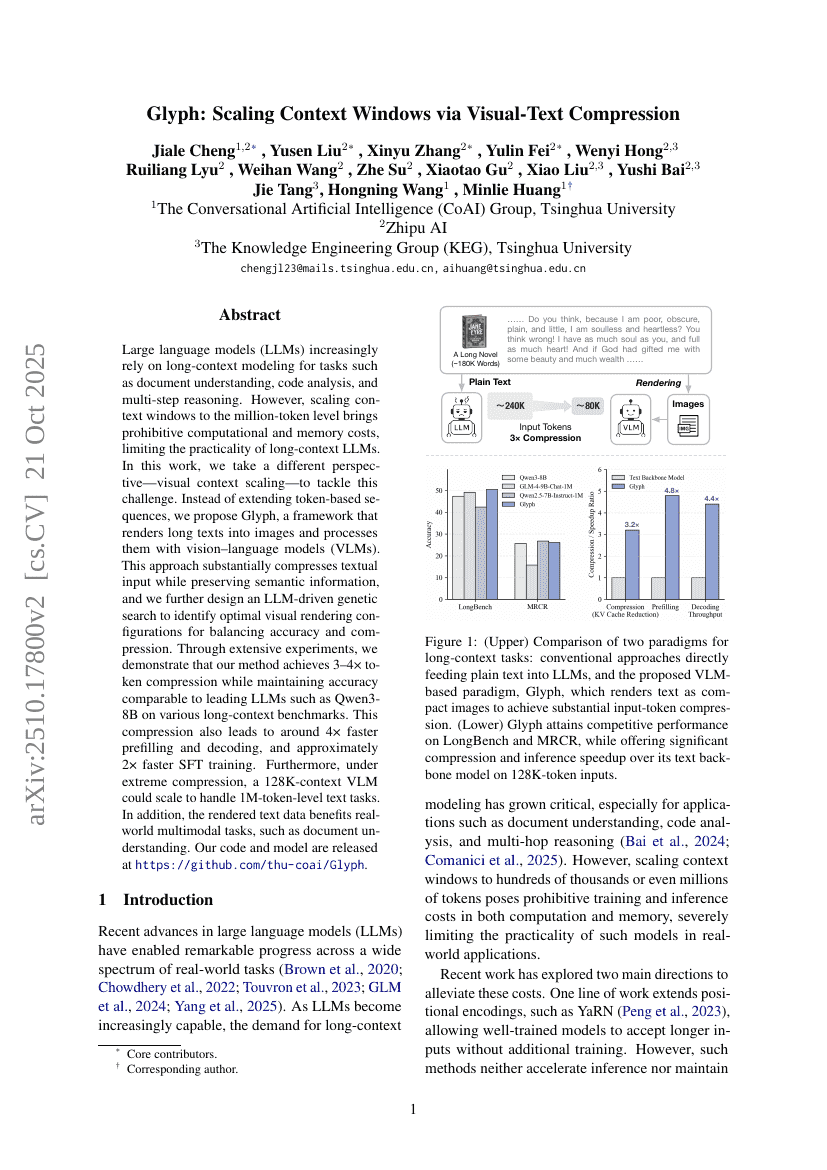
대규모 언어 모델(Large Language Models, LLMs)은 문서 이해, 코드 분석, 다단계 추론과 같은 과제에서 점점 더 긴 컨텍스트 모델링에 의존하고 있다. 그러나 컨텍스트 창을 백만 토큰 수준으로 확장하는 것은 계산 및 메모리 비용 측면에서 기하급수적으로 증가하여, 긴 컨텍스트 LLM의 실용성을 제한하는 주요 장애물이 되고 있다. 본 연구에서는 이 문제를 해결하기 위해 기존의 토큰 기반 시퀀스 연장 방식과는 다른 시각적 컨텍스트 확장(visual context scaling)의 관점을 제안한다. 토큰 기반 시퀀스를 연장하는 대신, 우리는 긴 텍스트를 이미지로 렌더링하고 비전-언어 모델(Vision-Language Models, VLMs)로 처리하는 프레임워크 Glyph를 제안한다. 이 접근법은 텍스트 입력을 상당히 압축하면서도 의미 정보를 유지할 수 있으며, 정확도와 압축률 간의 균형을 달성하기 위해 LLM 기반의 유전적 탐색(geometric search) 기법을 추가로 설계하였다. 광범위한 실험을 통해 제안한 방법이 다양한 긴 컨텍스트 벤치마크에서 Qwen3-8B와 같은 최첨단 LLM과 경쟁 가능한 정확도를 유지하면서도 3~4배의 토큰 압축을 달성함을 입증하였다. 이러한 압축은 약 4배 빠른 프리필링(filling) 및 디코딩 속도, 약 2배 빠른 SFT(지시어 기반 미세조정) 학습 속도를 초래한다. 더 나아가 극한의 압축 상황에서도, 128K 컨텍스트를 가진 VLM이 100만 토큰 수준의 텍스트 과제를 처리할 수 있도록 확장할 수 있음을 보였다. 또한, 렌더링된 텍스트 데이터는 문서 이해와 같은 실제 다중모달 과제에 유용한 이점을 제공한다. 본 연구의 코드와 모델은 https://github.com/thu-coai/Glyph 에 공개되어 있다.