Command Palette
Search for a command to run...
Minglei Shi Haolin Wang Wenzhao Zheng Ziyang Yuan Xiaoshi Wu Xintao Wang Pengfei Wan Jie Zhou Jiwen Lu
초록
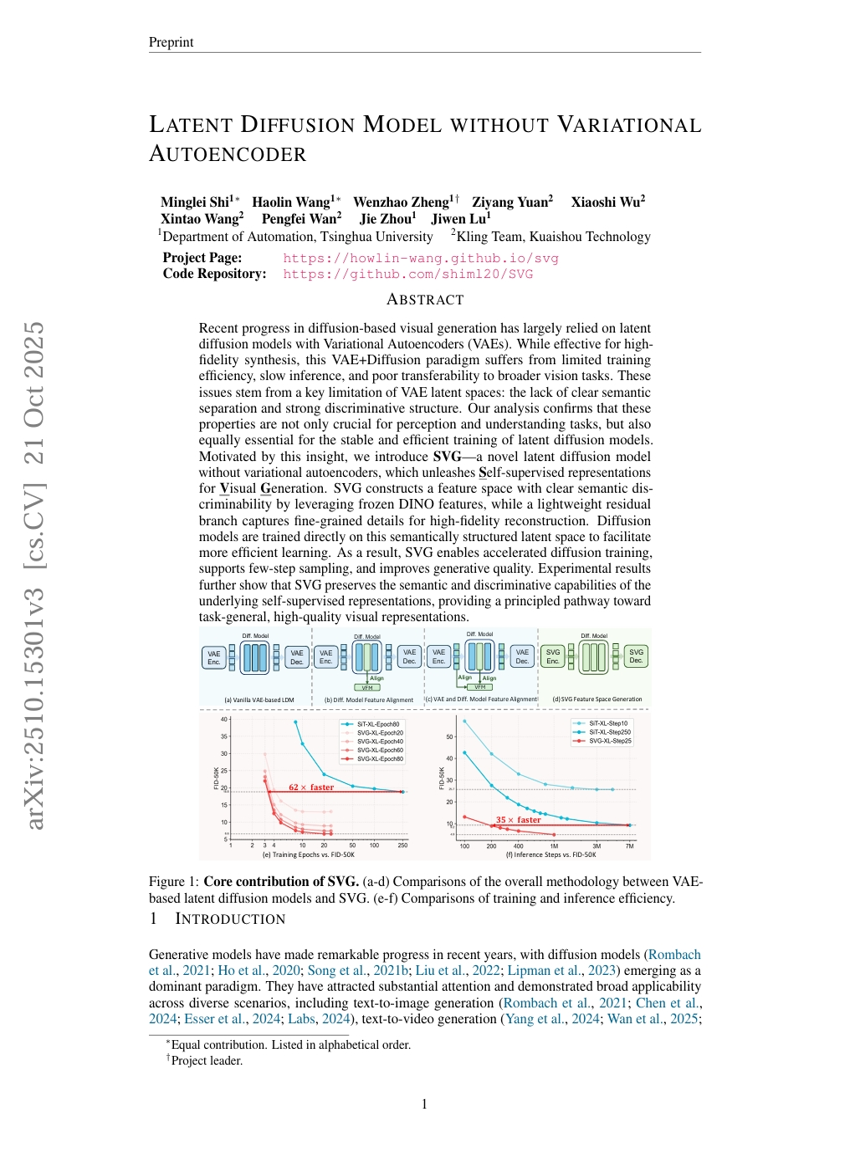
최근 확산 기반 시각 생성 기술의 발전은 변분 오토인코더(VAE)를 활용한 잠재 확산 모델에 크게 의존해왔다. 이러한 VAE + 확산 기반 접근법은 고해상도 생성 측면에서 효과적이지만, 훈련 효율성이 제한적이며 추론 속도가 느리고, 더 넓은 시각 작업으로의 전이성도 낮다는 문제가 있다. 이러한 문제들은 VAE의 잠재 공간이 가지는 핵심적 한계—명확한 의미적 분리와 강력한 구분 능력을 갖춘 구조의 부재—에서 기인한다. 우리의 분석은 이러한 특성이 인지 및 이해 작업뿐 아니라, 잠재 확산 모델의 안정적이고 효율적인 훈련에도 필수적임을 확인한다. 이러한 통찰에 기반하여, 우리는 변분 오토인코더 없이 작동하는 새로운 잠재 확산 모델인 SVG(Semantic-guided Variational-free Diffusion)를 제안한다. SVG는 자기지도 학습 기반 표현을 활용하여 시각 생성을 수행한다. SVG는 고정된 DINO 특징을 활용하여 의미적으로 명확하게 구분 가능한 특징 공간을 구성하며, 경량의 잔차 브랜치를 통해 세부적인 정보를 포착하여 고해상도 재구성 성능을 달성한다. 확산 모델은 이러한 의미적으로 구조화된 잠재 공간 위에서 직접 훈련되며, 이로 인해 더 효율적인 학습이 가능해진다. 결과적으로 SVG는 확산 훈련 속도를 가속화하고, 적은 단계의 샘플링을 지원하며 생성 품질을 향상시킨다. 실험 결과는 SVG가 기반 자율지도 표현의 의미적 및 구분 능력을 유지함을 보여주며, 일반화 가능한 고품질 시각 표현을 위한 체계적인 접근 방식을 제시한다.