Command Palette
Search for a command to run...
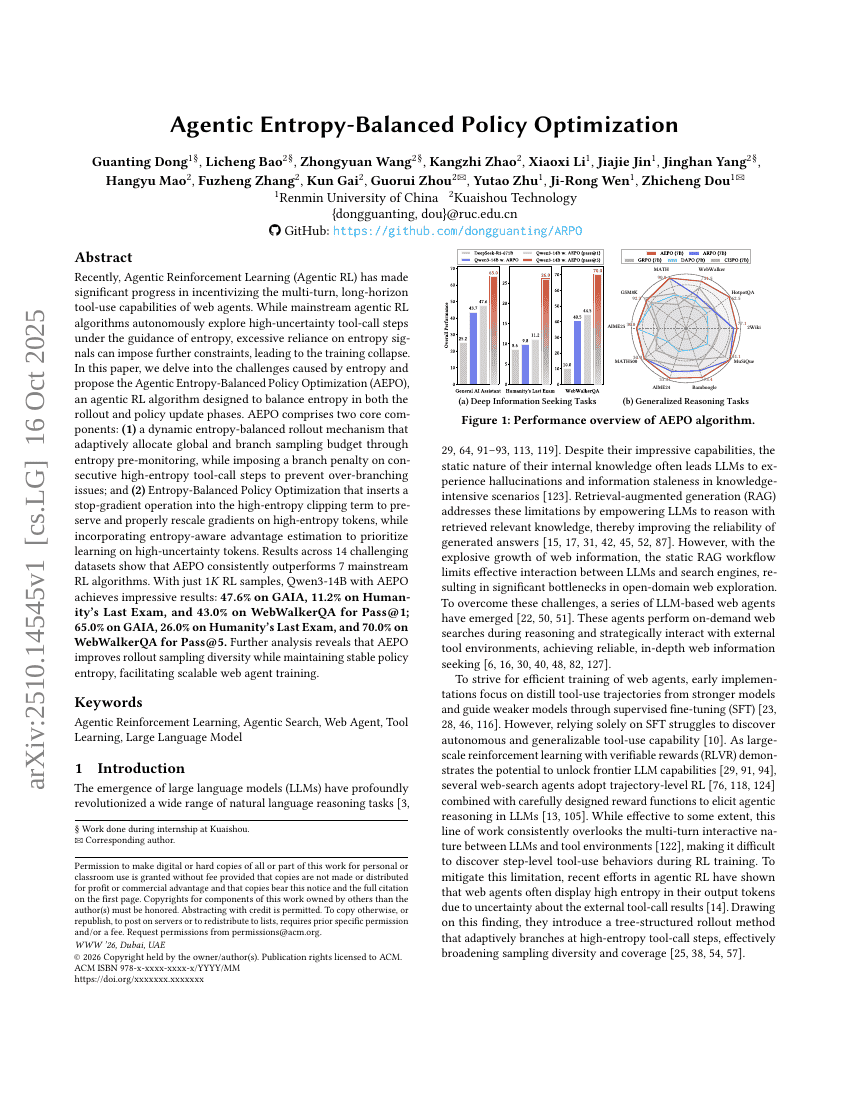
초록
최근 들어, 에이전트형 강화학습(Agentic Reinforcement Learning, Agentic RL)은 웹 에이전트의 다단계 및 장기적 도구 사용 능력을 유도하는 데 있어 중요한 진전을 이루었다. 기존 주류의 에이전트형 RL 알고리즘은 엔트로피 신호를 기반으로 하여 고불확실성 도구 호출 단계를 자율적으로 탐색하지만, 엔트로피 신호에 과도하게 의존할 경우 추가적인 제약이 발생하여 학습이 붕괴되는 문제가 존재한다. 본 논문에서는 엔트로피가 초래하는 문제를 심층적으로 분석하고, 롤아웃 및 정책 업데이트 단계에서 엔트로피를 균형 있게 조절할 수 있도록 설계된 ‘에이전트형 엔트로피 균형 정책 최적화(Agentic Entropy-Balanced Policy Optimization, AEPO)’ 알고리즘을 제안한다. AEPO는 다음과 같은 두 가지 핵심 구성 요소로 구성된다. (1) 동적 엔트로피 균형 롤아웃 메커니즘: 엔트로피 사전 모니터링을 통해 전역 및 분기 샘플링 예산을 적응적으로 배분하며, 연속적인 고엔트로피 도구 호출 단계에 대해 분기 페널티를 부과하여 과도한 분기 문제를 방지한다. (2) 엔트로피 균형 정책 최적화: 고엔트로피 클리핑 항목에 정지그래디언트(Stop-Gradient) 연산을 삽입하여 고엔트로피 토큰에 대한 그래디언트를 보존하고 적절히 재스케일링하며, 엔트로피 인지적 어드밴티지 추정을 도입하여 불확실성이 높은 토큰에 대한 학습을 우선적으로 수행한다. 14개의 도전적인 데이터셋에 대한 실험 결과, AEPO는 7종의 주류 RL 알고리즘을 일관되게 상회하는 성능을 보였다. 단 1,000개의 RL 샘플만으로도 Qwen3-14B에 AEPO를 적용한 모델은 다음과 같은 뛰어난 성과를 기록했다. Pass@1 기준으로 GAIA에서 47.6%, Humanity's Last Exam에서 11.2%, WebWalker에서 43.0%; Pass@5 기준으로 GAIA에서 65.0%, Humanity's Last Exam에서 26.0%, WebWalker에서 70.0%를 달성하였다. 추가 분석을 통해 AEPO가 롤아웃 샘플링의 다양성을 향상시키면서도 정책 엔트로피의 안정성을 유지함으로써, 확장 가능한 웹 에이전트 학습을 촉진함을 확인하였다.