Command Palette
Search for a command to run...
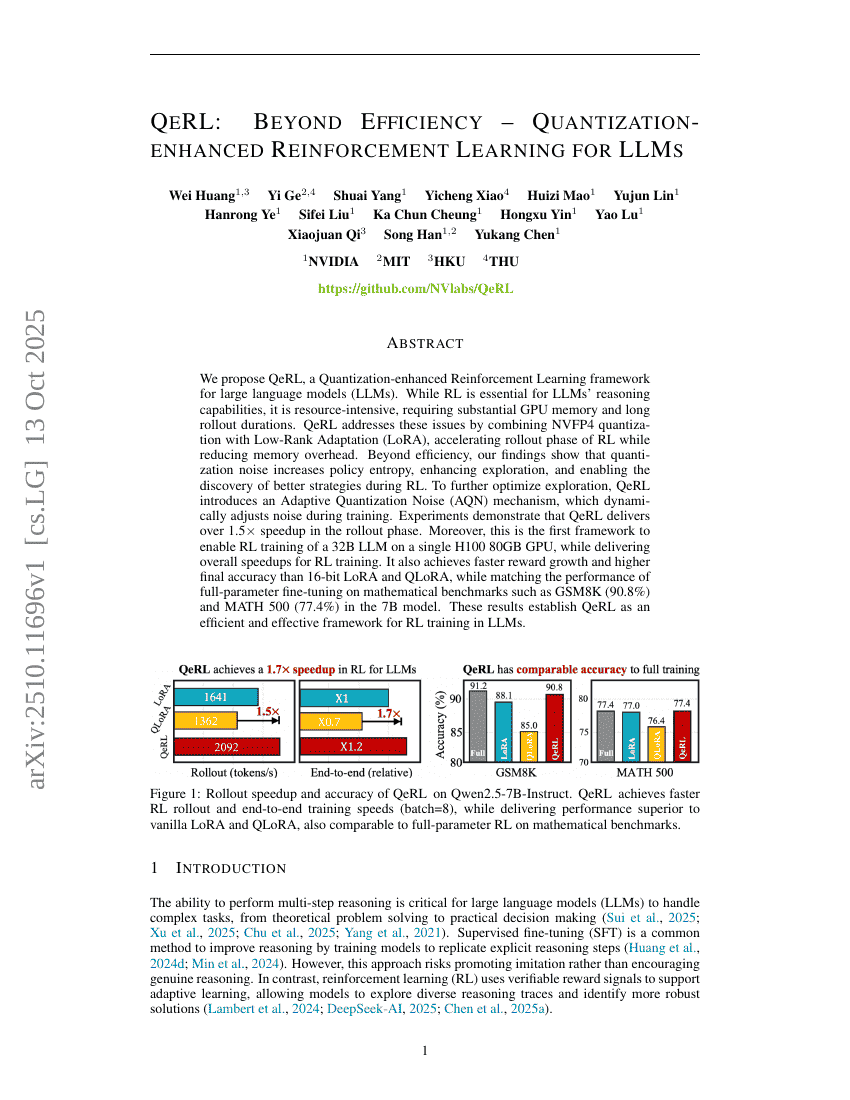
초록
우리는 대규모 언어 모델(LLM)을 위한 양자화 강화 학습(QeRL, Quantization-enhanced Reinforcement Learning) 프레임워크를 제안한다. 강화 학습(RL)은 LLM의 추론 능력에 필수적이지만, 고성능 GPU 메모리와 긴 롤아웃(rollout) 시간을 요구하는 등 자원 소모가 크다. QeRL은 NVFP4 양자화 기법과 저랭크 적응(LoRA, Low-Rank Adaptation)을 결합함으로써 RL의 롤아웃 단계를 가속화하면서도 메모리 부담을 줄이는 방식으로 이러한 문제를 해결한다. 효율성 외에도, 본 연구의 결과는 양자화 노이즈가 정책 엔트로피를 증가시켜 탐색 태도를 향상시킴으로써 강화 학습 과정에서 더 우수한 전략을 탐색할 수 있음을 보여준다. 탐색 성능을 further 최적화하기 위해 QeRL은 학습 중에 노이즈를 동적으로 조정하는 적응형 양자화 노이즈(AQN, Adaptive Quantization Noise) 메커니즘을 도입한다. 실험 결과, QeRL은 롤아웃 단계에서 1.5배 이상의 속도 향상을 달성함을 입증했다. 더불어, QeRL은 단일 H100 80GB GPU에서 32B 규모의 LLM에 대한 강화 학습을 가능하게 하는 최초의 프레임워크이며, 전체적인 강화 학습 훈련 속도 향상도 제공한다. 또한, 16비트 LoRA 및 QLoRA 대비 더 빠른 보상 증가와 높은 최종 정확도를 달성했으며, 7B 규모 모델에서 수학 기준 평가 벤치마크인 GSM8K(90.8%)와 MATH 500(77.4%)에서 전파라미터 미세조정(full-parameter fine-tuning) 수준의 성능을 유지한다. 이러한 결과는 QeRL이 LLM의 강화 학습 훈련에 있어 효율적이고 효과적인 프레임워크임을 입증한다.