Command Palette
Search for a command to run...
Jinghao Zhang Naishan Zheng Ruilin Li Dongzhou Cheng Zheming Liang Feng Zhao Jiaqi Wang
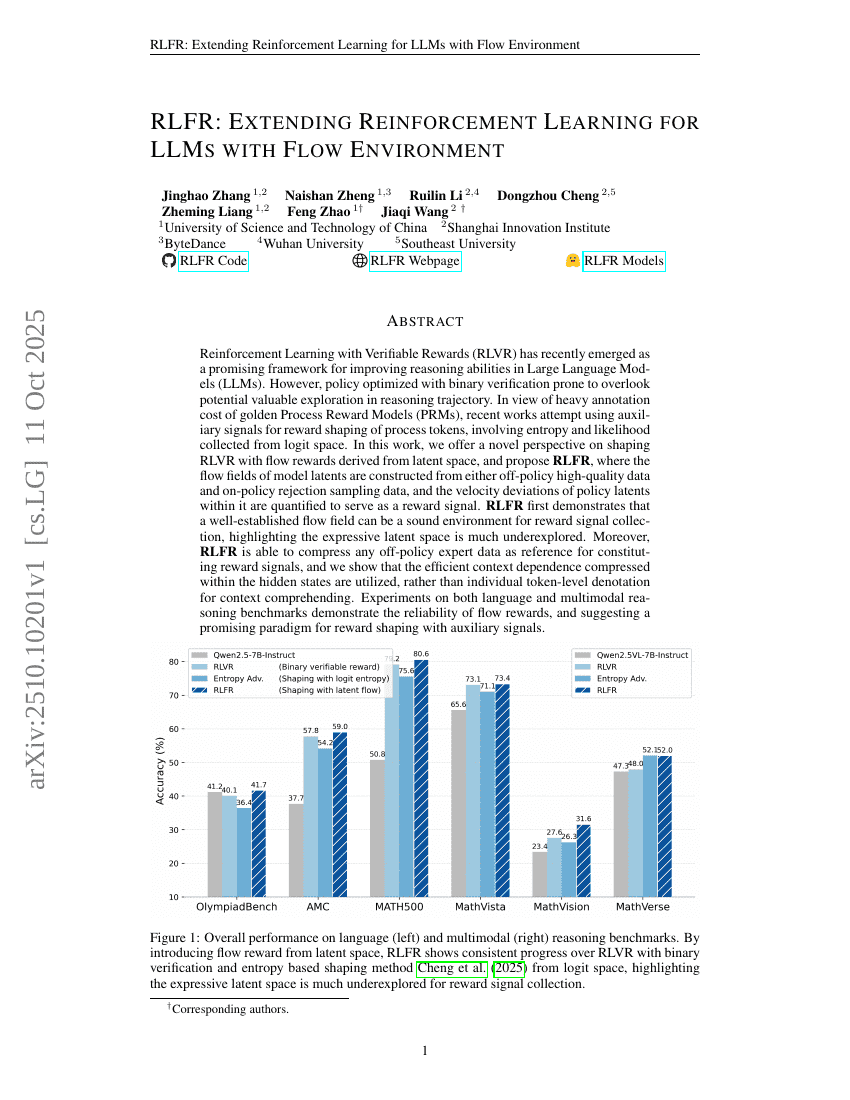
초록
최근 들어, 보상 검증(Verifiable Rewards)을 활용한 강화학습(RLVR)은 대규모 언어 모델(LLM)의 추론 능력을 향상시키기 위한 유망한 프레임워크로 부상하고 있다. 그러나 이진 검증(binary verification)을 기반으로 최적화된 정책은 추론 경로 내 잠재적인 유용한 탐색을 간과할 수 있다는 문제가 있다. 골든 프로세스 리워드 모델(PRMs)의 높은 주석 비용을 고려할 때, 최근 연구들은 로짓 공간에서 수집한 엔트로피와 가능도 등의 보조 신호를 활용하여 프로세스 토큰의 보상 구조를 형성하려는 시도를 하고 있다. 본 연구에서는 잠재 공간(latent space)에서 유도된 흐름 보상(flow rewards)을 활용한 RLVR의 새로운 관점을 제안하며, 이를 바탕으로 RLFR(Reinforcement Learning with Flow Rewards)를 제안한다. RLFR는 정책의 잠재 표현 내에서, 비정책(Off-policy) 고품질 데이터 또는 정책 내 거부 샘플링(Rejection Sampling) 데이터로부터 모델 잠재 표현의 흐름 장(field)을 구성하고, 정책 잠재 표현의 속도 편차를 정량화하여 보상 신호로 활용한다. RLFR는 잘 정립된 흐름 장이 보상 신호 수집에 적합한 환경이 될 수 있음을 처음으로 입증하며, 표현력이 풍부한 잠재 공간이 여전히 심층적으로 탐색되지 않았음을 강조한다. 더불어 RLFR는 비정책 전문가 데이터를 효율적으로 압축하여 보상 신호 구성의 기준(reference)으로 활용할 수 있으며, 히든 상태 내에 압축된 효율적인 컨텍스트 의존성(context dependence)이 개별 토큰 수준의 의미 해석보다 더 효과적으로 활용됨을 보여준다. 언어 및 다중모달 추론 벤치마크에서 수행된 실험을 통해 흐름 보상의 신뢰성과 보조 신호를 활용한 보상 구조 형성의 전망 있는 패러다임을 입증하였다.