Command Palette
Search for a command to run...
Yi Lu Jianing Wang Linsen Guo Wei He Hongyin Tang Tao Gui Xuanjing Huang Xuezhi Cao Wei Wang Xunliang Cai
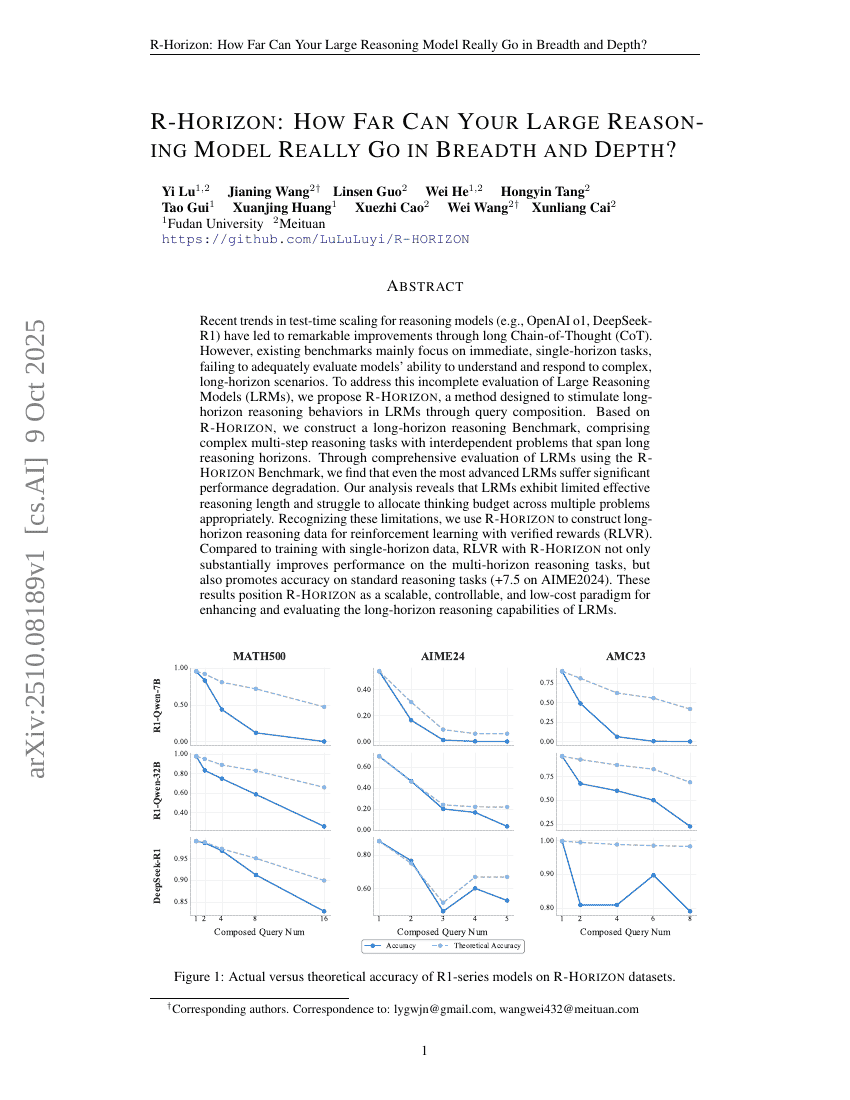
초록
최근 추론 모델(예: OpenAI o1, DeepSeek-R1)의 테스트 시 스케일링(training-time scaling)에 대한 연구 동향은 긴 체인 오브 써포트(Chain-of-Thought, CoT)를 통해 놀라운 성능 향상을 이끌어내고 있다. 그러나 기존의 평가 벤치마크는 주로 즉각적이고 단일 수준의 과제에 집중되어 있어, 복잡한 장기적 시나리오에 대한 이해 및 대응 능력을 충분히 평가하지 못하고 있다. 이러한 대규모 추론 모델(Large Reasoning Models, LRMs)에 대한 평가의 한계를 보완하기 위해, 우리는 질의 조합을 통해 LRMs의 장기적 추론 행동을 유도하는 R-HORIZON을 제안한다. R-HORIZON 기반으로, 서로 의존적인 다단계 복잡한 문제들이 장기적인 추론 수준에 걸쳐 구성된 장기적 추론 벤치마크를 구축하였다. R-HORIZON 벤치마크를 활용한 종합적인 LRMs 평가 결과, 가장 최신의 LRMs 역시 상당한 성능 저하를 겪는 것으로 나타났다. 분석을 통해 LRMs는 제한된 유효 추론 길이를 가지며, 다수의 문제에 걸쳐 사고 예산(thinking budget)을 적절히 배분하는 데 어려움을 겪는다는 점이 밝혀졌다. 이러한 한계를 인지한 우리는, R-HORIZON을 활용하여 보상이 검증된 강화학습(Reinforcement Learning with Verified Rewards, RLVR)을 위한 장기적 추론 데이터를 구축하였다. 단일 수준 데이터로 학습하는 것과 비교하여, R-HORIZON을 활용한 RLVR은 다수 수준 추론 과제에서 성능을 크게 향상시킬 뿐만 아니라, 기존의 표준 추론 과제에서도 정확도를 개선하였으며, AIME2024에서 7.5점의 성능 향상이 확인되었다. 이러한 결과는 R-HORIZON이 LRMs의 장기적 추론 능력을 향상시키고 평가하는 데 있어 확장 가능하고 제어 가능하며 저비용의 패러다임으로서의 잠재력을 지닌다는 것을 시사한다.