Command Palette
Search for a command to run...
Shijian Deng Kai Wang Tianyu Yang Harsh Singh Yapeng Tian
초록
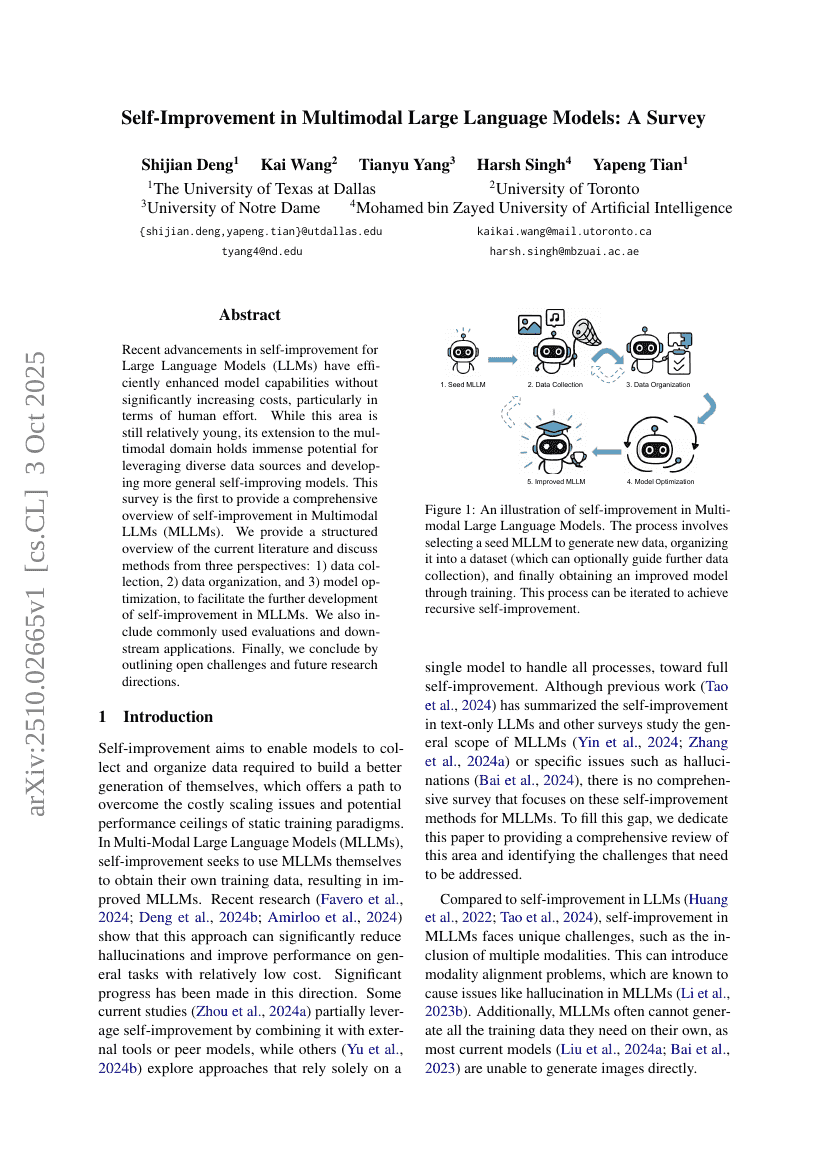
최근 대규모 언어 모델(Large Language Models, LLMs)의 자기 개선 기술은 인간의 노력 측면에서 큰 증가 없이도 모델의 성능을 효율적으로 향상시키는 데 성공했다. 이 분야는 여전히 비교적 초기 단계에 있지만, 다중모달 영역으로의 확장은 다양한 데이터 소스를 활용하고 더 일반화된 자기 개선 모델을 개발할 수 있는 막대한 잠재력을 지닌다. 본 조사 보고서는 다중모달 대규모 언어 모델(Multimodal LLMs, MLLMs)의 자기 개선 기술에 대해 종합적으로 개괄하는 최초의 논문이다. 우리는 현재의 문헌을 체계적으로 정리하고, 데이터 수집, 데이터 정리, 모델 최적화의 세 가지 관점에서 기존의 방법들을 논의함으로써 MLLMs의 자기 개선 기술 발전을 촉진하고자 한다. 또한 자주 사용되는 평가 방법과 하류 응용 사례도 포함하였다. 마지막으로, 여전히 남아 있는 열린 과제와 향후 연구 방향을 제시하며 결론을 맺는다.