Command Palette
Search for a command to run...
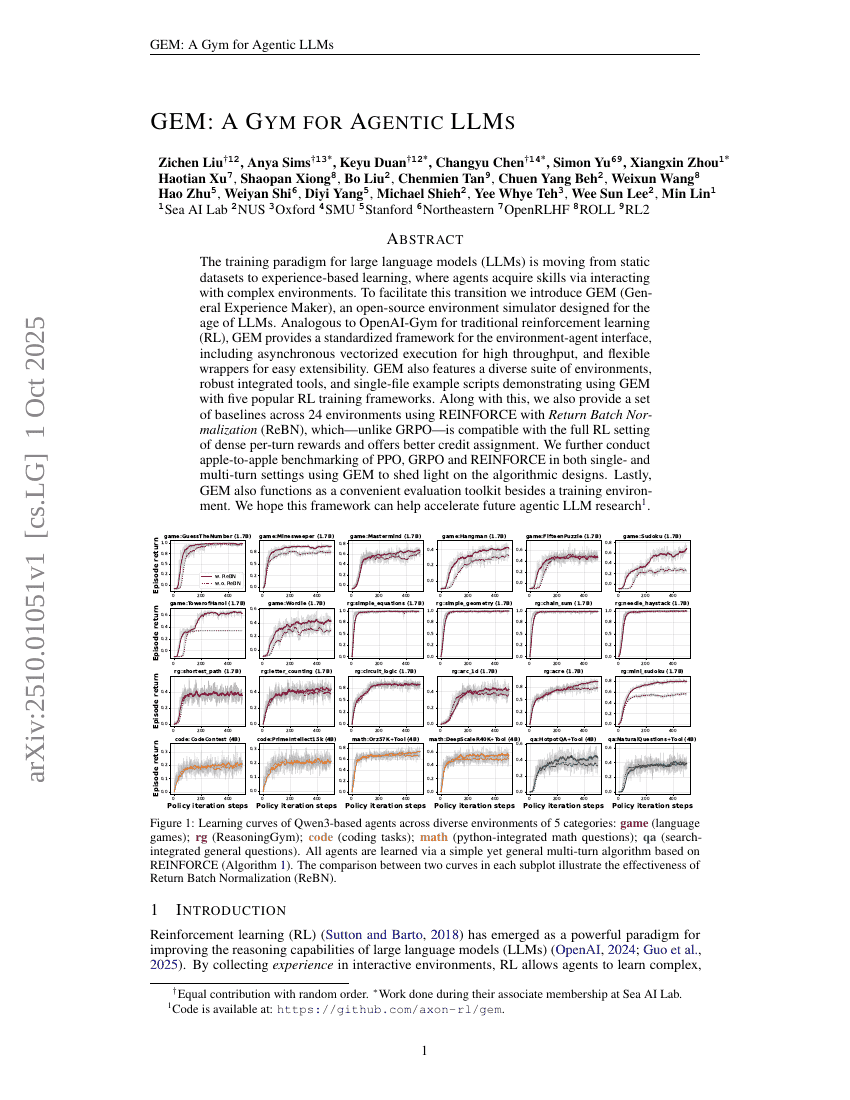
초록
대규모 언어 모델(LLM)의 학습 패러다임은 고정된 데이터셋에서 벗어나, 복잡한 환경과의 상호작용을 통해 기술을 습득하는 경험 기반 학습으로 진화하고 있다. 이러한 전환을 촉진하기 위해 우리는 LLM 시대를 위한 환경 시뮬레이터인 GEM(General Experience Maker)을 소개한다. 기존 강화학습(RL)에서 OpenAI-Gym과 유사하게, GEM은 환경-에이전트 인터페이스를 표준화한 프레임워크를 제공하며, 높은 처리량을 위한 비동기 벡터화 실행과 확장성 향상을 위한 유연한 래퍼를 포함한다. 또한 GEM은 다양한 환경 세트, 강력한 통합 도구, 그리고 다섯 가지 인기 있는 강화학습 학습 프레임워크와 함께 GEM을 사용하는 방법을 보여주는 단일 파일 기반 예제 스크립트를 제공한다. 더불어, 밀도 높은 턴별 보상이 가능한 전형적인 강화학습 설정에 호환되며, GRPO와 달리 더 나은 보상 할당을 제공하는 Return Batch Normalization(ReBN)을 사용한 REINFORCE 기반 베이스라인을 24개의 환경에서 제공한다. 이를 바탕으로 GEM을 활용해 단일 턴 및 다중 턴 설정에서 PPO, GRPO, REINFORCE의 성능을 동일한 조건에서 비교 평가함으로써 알고리즘 설계에 대한 통찰을 제공한다. 마지막으로, GEM은 학습 환경에 그치지 않고 평가 도구로도 유용하게 활용될 수 있다. 본 연구가 향후 에이전트 기반 LLM 연구의 가속화에 기여하기를 기대한다.