Command Palette
Search for a command to run...
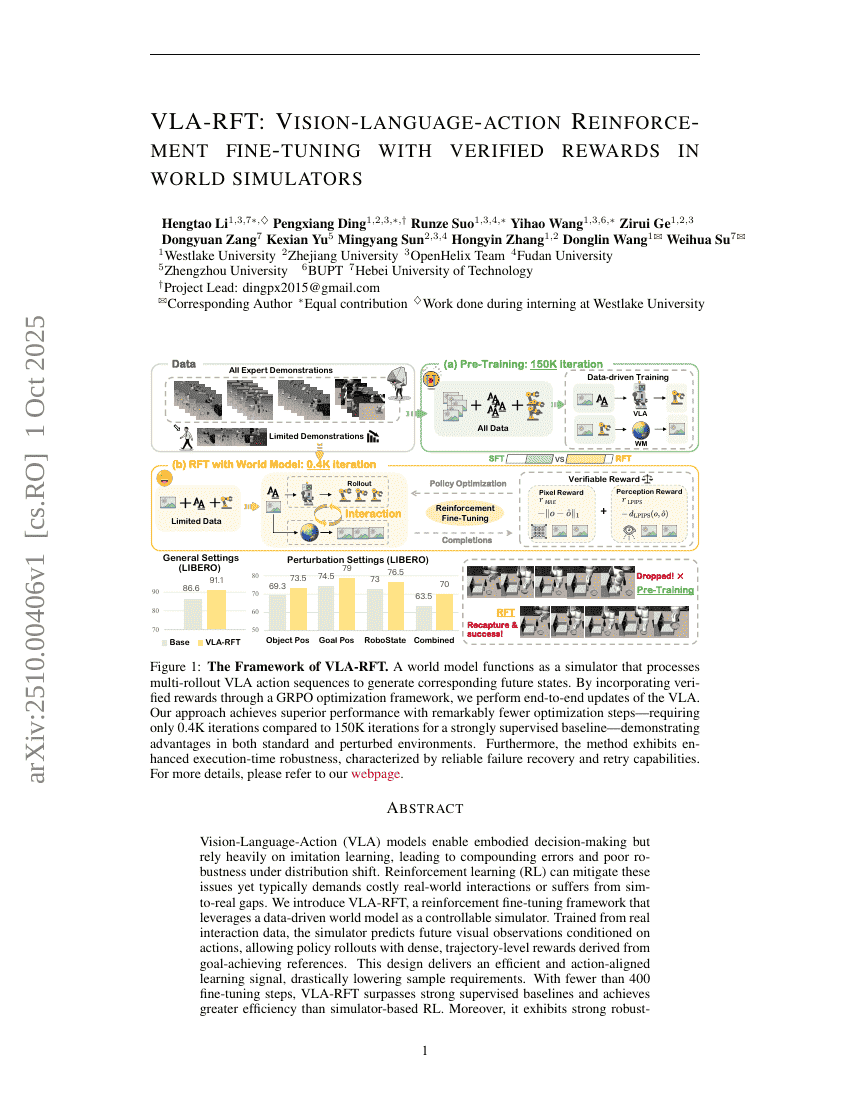
초록
시각-언어-행동(Vision-Language-Action, VLA) 모델은 몸체화된 의사결정을 가능하게 하지만, 몰입 학습(imitation learning)에 크게 의존하여 분포 변화(distribution shift) 상황에서 오류가 누적되고 저항성이 낮은 문제가 있다. 강화 학습(Reinforcement Learning, RL)은 이러한 문제를 완화할 수 있으나 일반적으로 비용이 큰 실제 환경 상호작용을 필요로 하거나 시뮬레이션-실세계 간 격차(sim-to-real gap)에 취약하다. 본 연구에서는 데이터 기반의 세계 모델(world model)을 가용 가능한 시뮬레이터로 활용하는 강화 학습 미세조정(Reinforcement Fine-Tuning, RFT) 프레임워크인 VLA-RFT를 제안한다. 실제 상호작용 데이터로부터 학습된 이 시뮬레이터는 행동(action)을 조건으로 미래의 시각적 관측값을 예측할 수 있으며, 목표 달성 기준(reference)을 기반으로 밀도 높은, 궤적 수준의 보상을 도출해 정책(policy) 전개를 가능하게 한다. 이러한 설계는 효율적이고 행동과 일치하는 학습 신호를 제공하여 샘플 요구량을 크게 감소시킨다. 400회 미만의 미세조정 단계만으로도 VLA-RFT는 강력한 지도 학습 기반의 기준 모델을 초월하며, 시뮬레이터 기반 RL보다 뛰어난 효율성을 보였다. 더불어, 외부 간섭 조건 하에서도 뛰어난 강건성(robustness)을 보이며 안정적인 작업 수행이 가능하다. 본 연구 결과는 세계 모델 기반의 RFT가 VLA 모델의 일반화 능력과 강건성을 향상시키는 실용적인 사후 훈련 파라다임임을 입증한다. 자세한 내용은 https://vla-rft.github.io/ 를 참조하시기 바랍니다.