Command Palette
Search for a command to run...
Chengyue Wu Hao Zhang Shuchen Xue Shizhe Diao Yonggan Fu Zhijian Liu Pavlo Molchanov Ping Luo Song Han Enze Xie
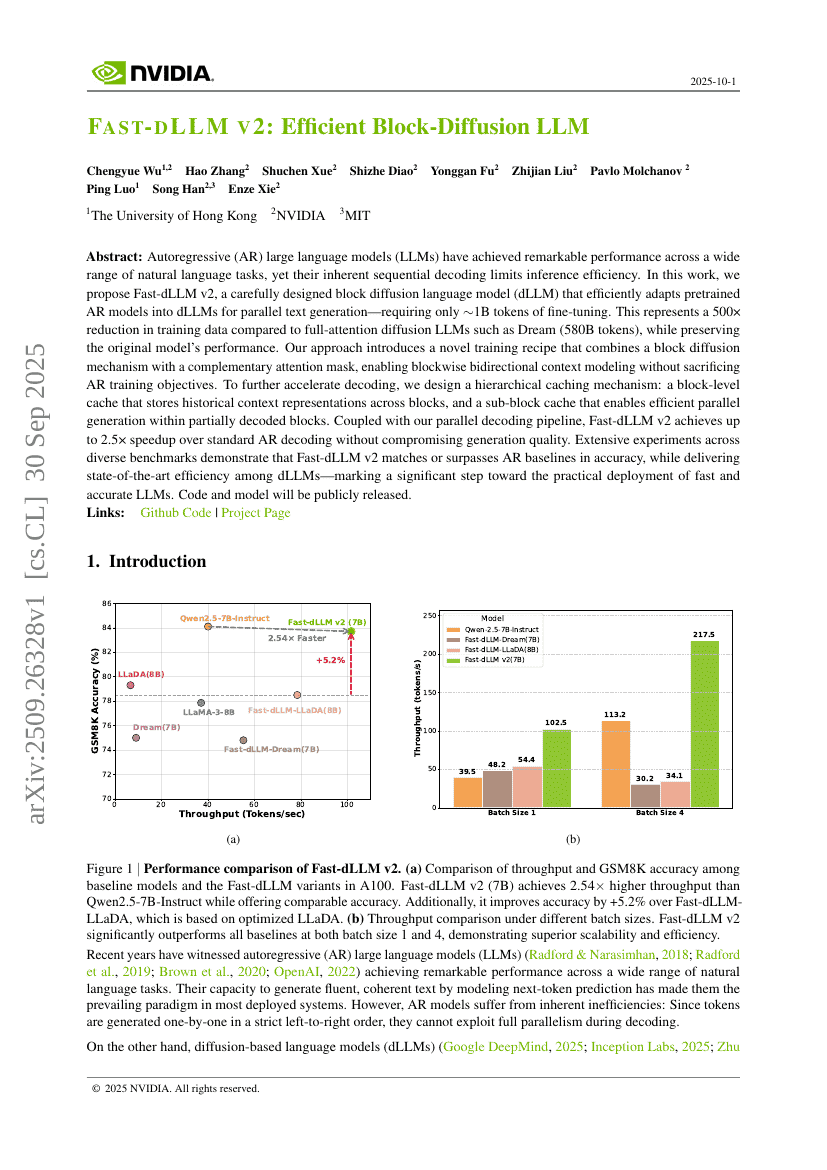
초록
자기회귀(Autoregressive, AR) 대규모 언어 모델(Large Language Models, LLMs)은 다양한 자연어 처리 과제에서 뛰어난 성능을 달성했으나, 본질적으로 순차적 디코딩 방식으로 인해 추론 효율성이 제한된다. 본 연구에서는 사전 훈련된 AR 모델을 병렬 텍스트 생성에 효과적으로 변환할 수 있는 블록 확산 언어 모델(Block Diffusion Language Model, dLLM)인 Fast-dLLM v2를 제안한다. 이 모델은 약 10억 토큰의 미세조정만으로 기존 AR 모델을 dLLM으로 전환할 수 있으며, 이는 Dream과 같은 전체 주의력(attention) 확산 LLM(5800억 토큰)에 비해 훈련 데이터를 약 500배 감소시킨 것이다. 동시에 원래 모델의 성능을 유지한다. 본 연구의 핵심은 새로운 훈련 방법론을 도입한 것으로, 블록 확산 기법과 보완적인 주의 마스크(attention mask)를 결합하여, AR 훈련 목표를 희생하지 않으면서도 블록 단위의 양방향 컨텍스트 모델링을 가능하게 한다. 또한 추론 속도를 further 향상시키기 위해 계층적 캐싱 메커니즘을 설계하였다. 이는 블록 단위의 캐시를 통해 블록 간 역사적 컨텍스트 표현을 저장하고, 하위 블록 단위 캐시를 통해 부분적으로 디코딩된 블록 내에서 효율적인 병렬 생성을 가능하게 한다. 이러한 캐싱 메커니즘과 병렬 디코딩 파이프라인을 결합함으로써, Fast-dLLM v2는 생성 품질에 손상을 주지 않으면서도 표준 AR 디코딩 대비 최대 2.5배의 속도 향상을 달성한다. 다양한 벤치마크에서 실시한 광범위한 실험 결과는 Fast-dLLM v2가 정확도 측면에서 AR 기준 모델과 동등하거나 이를 초월함을 보여주며, dLLM 중에서도 최고 수준의 효율성을 제공함으로써 빠르고 정확한 LLM의 실용적 적용을 위한 중대한 전환점을 마련한다. 코드와 모델은 공개될 예정이다.