Command Palette
Search for a command to run...
Haoran He Yuxiao Ye Qingpeng Cai Chen Hu Binxing Jiao Daxin Jiang Ling Pan
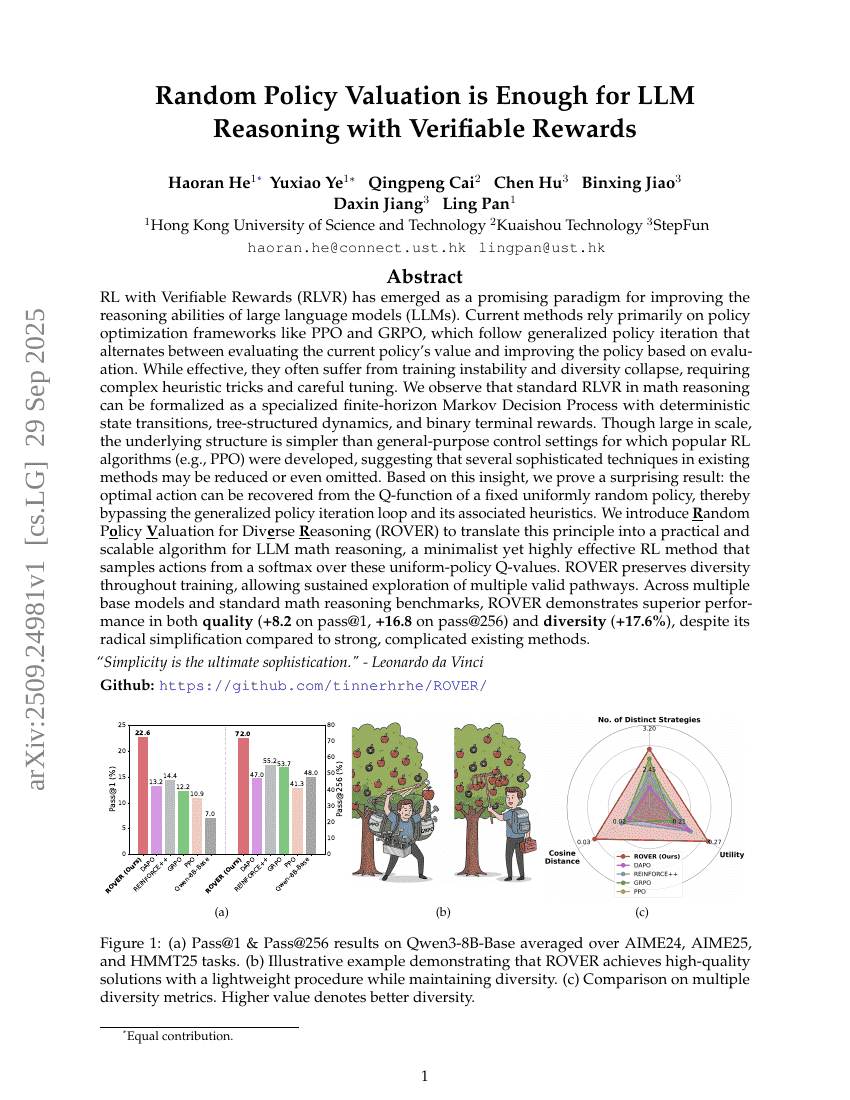
초록
확인 가능한 보상(Verifiable Rewards)을 활용한 강화학습(RLVR)은 대규모 언어 모델(LLM)의 추론 능력을 향상시키기 위한 유망한 패러다임으로 부상하고 있다. 기존의 방법들은 주로 PPO와 GRPO와 같은 정책 최적화 프레임워크에 의존하며, 이는 현재 정책의 가치를 평가하고 평가 결과를 바탕으로 정책을 개선하는 과정을 반복하는 일반화된 정책 반복(generalized policy iteration) 방식을 따르고 있다. 이러한 방법은 효과적이나, 훈련의 불안정성과 다양성 붕괴(diversity collapse) 문제를 자주 겪으며, 복잡한 히우리스틱 기법과 세심한 하이퍼파라미터 튜닝이 필요하다. 우리는 수학 추론에서 일반적인 RLVR가 결정론적 상태 전이, 트리 구조의 동역학, 이진 종료 보상이 특징인 특수한 유한 시간 마르코프 결정 과정(finite-horizon Markov Decision Process)으로 수학적으로 형식화될 수 있음을 관찰했다. 규모는 크지만, 기존의 인기 있는 강화학습 알고리즘(PPO 등)이 개발된 일반적인 제어 설정보다 구조가 더 단순함을 확인할 수 있었으며, 이는 기존 방법에 포함된 여러 복잡한 기술들이 축소되거나 제거될 수 있음을 시사한다. 이러한 통찰을 바탕으로, 우리는 놀라운 결과를 입증한다: 고정된 균일한 랜덤 정책의 Q-함수로부터 최적의 행동을 복원할 수 있음을 보였다. 이는 일반화된 정책 반복 루프와 그에 수반되는 히우리스틱을 완전히 회피할 수 있음을 의미한다. 이를 실용적이고 확장 가능한 LLM 수학 추론 알고리즘으로 구현하기 위해, 다각적인 추론을 위한 랜덤 정책 평가(Random Policy Valuation for Diverse Reasoning, ROVER)를 제안한다. ROVER는 균일한 정책에 대한 Q-값을 기반으로 소프트맥스를 통해 행동을 샘플링하는 최소주의(minimalist)이지만 매우 효과적인 강화학습 방법이다. ROVER는 훈련 전반에 걸쳐 추론의 다양성을 유지하며, 여러 유효한 추론 경로를 꾸준히 탐색할 수 있도록 한다. 다양한 기본 모델과 표준 수학 추론 벤치마크에서, 기존의 강력하고 복잡한 방법들과 비교해도 ROVER는 품질(패스@1 기준 +8.2, 패스@256 기준 +16.8)과 다양성(+17.6%) 측면에서 뛰어난 성능을 보였다.