Command Palette
Search for a command to run...
Yuxiang Ji Ziyu Ma Yong Wang Guanhua Chen Xiangxiang Chu Liaoni Wu
초록
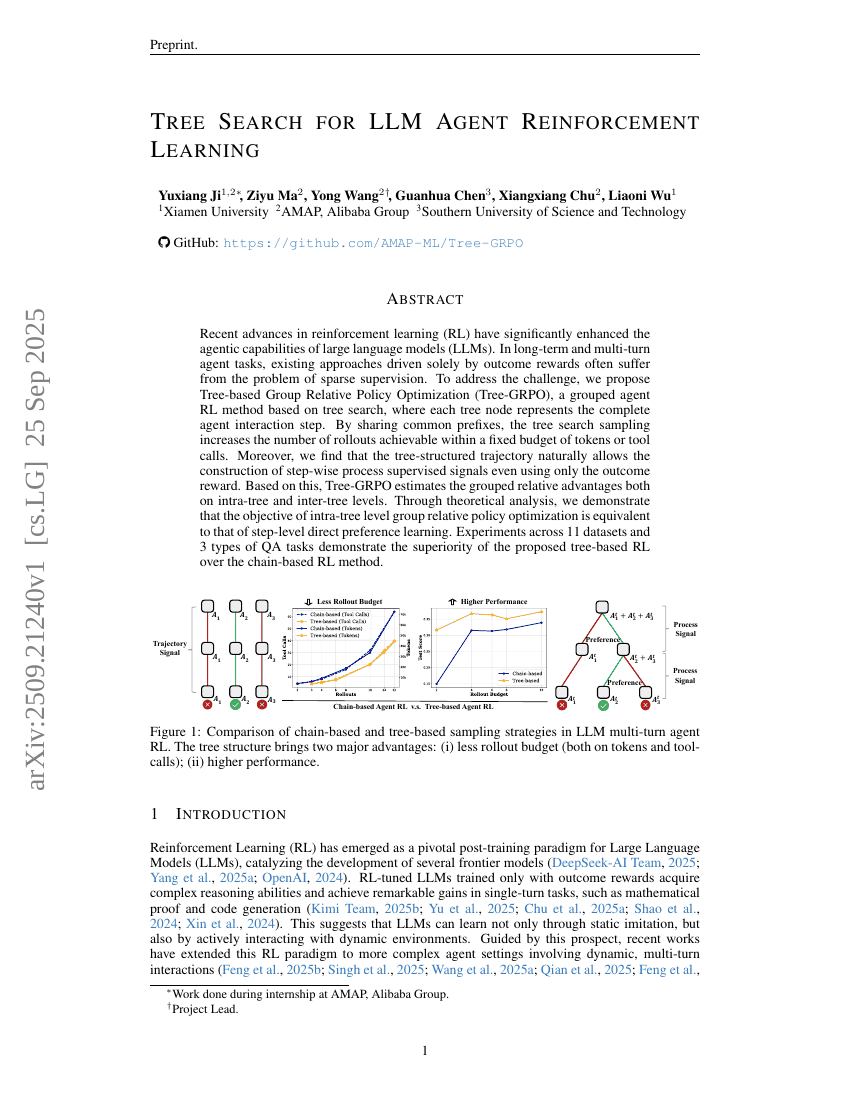
최근 강화학습(RL) 분야의 발전은 대규모 언어모델(LLM)의 에이전트 기능을 크게 향상시켰다. 장기적이고 다단계의 에이전트 작업에서, 기존의 결과 보상에만 기반한 접근 방식은 희소한 감독 문제에 자주 직면한다. 이 문제를 해결하기 위해 우리는 트리 기반 그룹 상대적 정책 최적화(Tree-GRPO)를 제안한다. 이는 트리 탐색 기반의 그룹화된 에이전트 강화학습 방법으로, 각 트리 노드는 에이전트의 전체 상호작용 단계를 나타낸다. 공통된 접두사(공통 프리픽스)를 공유함으로써 트리 탐색 샘플링은 고정된 토큰 또는 도구 호출 예산 내에서 가능한 롤아웃 수를 증가시킨다. 또한, 트리 구조의 추적 경로는 단계별 프로세스 감독 신호를 결과 보상만을 사용해도 자연스럽게 구성할 수 있음을 발견했다. 이를 바탕으로 Tree-GRPO는 트리 내부 및 트리 간 수준에서 그룹 상대적 이익을 추정한다. 이론적 분석을 통해 트리 내부 수준의 그룹 상대적 정책 최적화 목적함수가 단계 수준의 직접 선호 학습과 동치임을 입증하였다. 11개 데이터셋과 3종류의 질의응답(QA) 작업을 대상으로 한 실험 결과, 제안한 트리 기반 강화학습이 체인 기반 강화학습보다 우수함을 확인하였다.