Command Palette
Search for a command to run...
초록
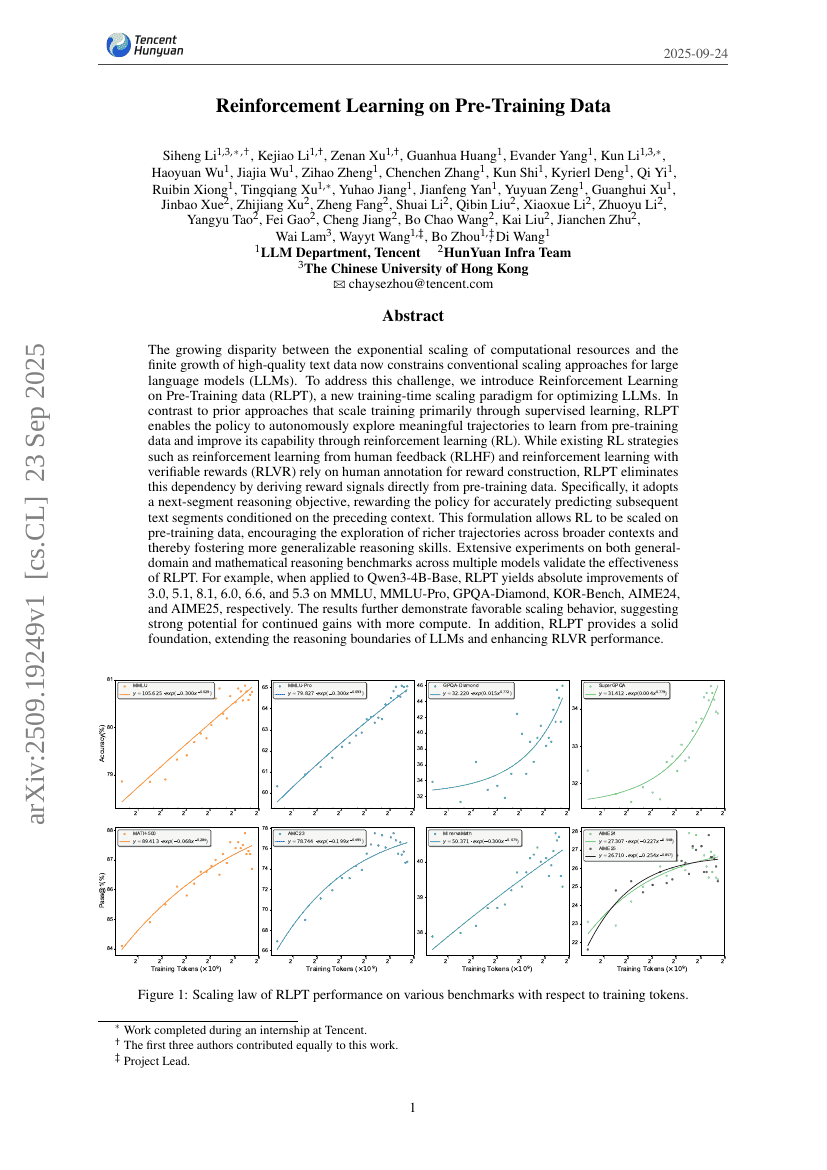
계산 자원의 지수적 증가와 고품질 텍스트 데이터의 유한한 성장 간 격차가 점점 커지면서, 기존의 대규모 언어 모델(Large Language Models, LLMs)에 대한 규모 확장 전략에 한계가 생기고 있다. 이 문제를 해결하기 위해, 우리는 사전 훈련 데이터를 기반으로 한 강화학습(Reinforcement Learning on Pre-Training data, RLPT)이라는 새로운 훈련 시점 규모 확장 패러다임을 제안한다. 기존의 주로 지도학습을 통해 훈련을 확장하는 접근 방식과 달리, RLPT는 정책(policy)이 사전 훈련 데이터로부터 의미 있는 탐색 경로를 자율적으로 탐색하고, 강화학습(Reinforcement Learning, RL)을 통해 능력을 향상시킬 수 있도록 한다. 기존의 강화학습 전략인 인간 피드백 기반 강화학습(RLHF, Reinforcement Learning from Human Feedback)이나 검증 가능한 보상 기반 강화학습(RLVR, Reinforcement Learning with Verifiable Rewards)은 보상 생성을 위해 인간의 주석(annotation)에 의존하지만, RLPT는 사전 훈련 데이터로부터 직접 보상 신호를 도출함으로써 이러한 의존성을 제거한다. 구체적으로, 다음 세그먼트 추론 목적함수(next-segment reasoning objective)를 채택하여, 앞선 문맥을 기반으로 다음 텍스트 세그먼트를 정확히 예측하는 정책에 보상을 부여한다. 이러한 설정은 강화학습을 사전 훈련 데이터 기반으로 확장할 수 있게 하여, 더 넓은 문맥에서 풍부한 탐색 경로를 유도하고, 더 일반화 가능한 추론 능력을 향상시키는 데 기여한다. 다양한 모델을 대상으로 일반 도메인 및 수학적 추론 벤치마크에서 실시한 광범위한 실험을 통해 RLPT의 효과성이 입증되었다. 예를 들어, Qwen3-4B-Base에 적용했을 때, MMLU, MMLU-Pro, GPQA-Diamond, KOR-Bench, AIME24, AIME25에서 각각 3.0, 5.1, 8.1, 6.0, 6.6, 5.3의 절대적 성능 향상이 나타났다. 결과는 유리한 규모 확장 특성을 보이며, 더 많은 계산 자원을 활용할 경우 지속적인 성능 향상이 가능할 것으로 보인다. 또한 RLPT는 LLM의 추론 능력 경계를 확장하고, RLVR 성능을 향상시키는 견고한 기반을 제공함으로써, 향후 연구에 중요한 기여를 할 것으로 기대된다.