Command Palette
Search for a command to run...
Kaiwen Zheng Huayu Chen Haotian Ye Haoxiang Wang Qinsheng Zhang Kai Jiang Hang Su Stefano Ermon Jun Zhu Ming-Yu Liu
초록
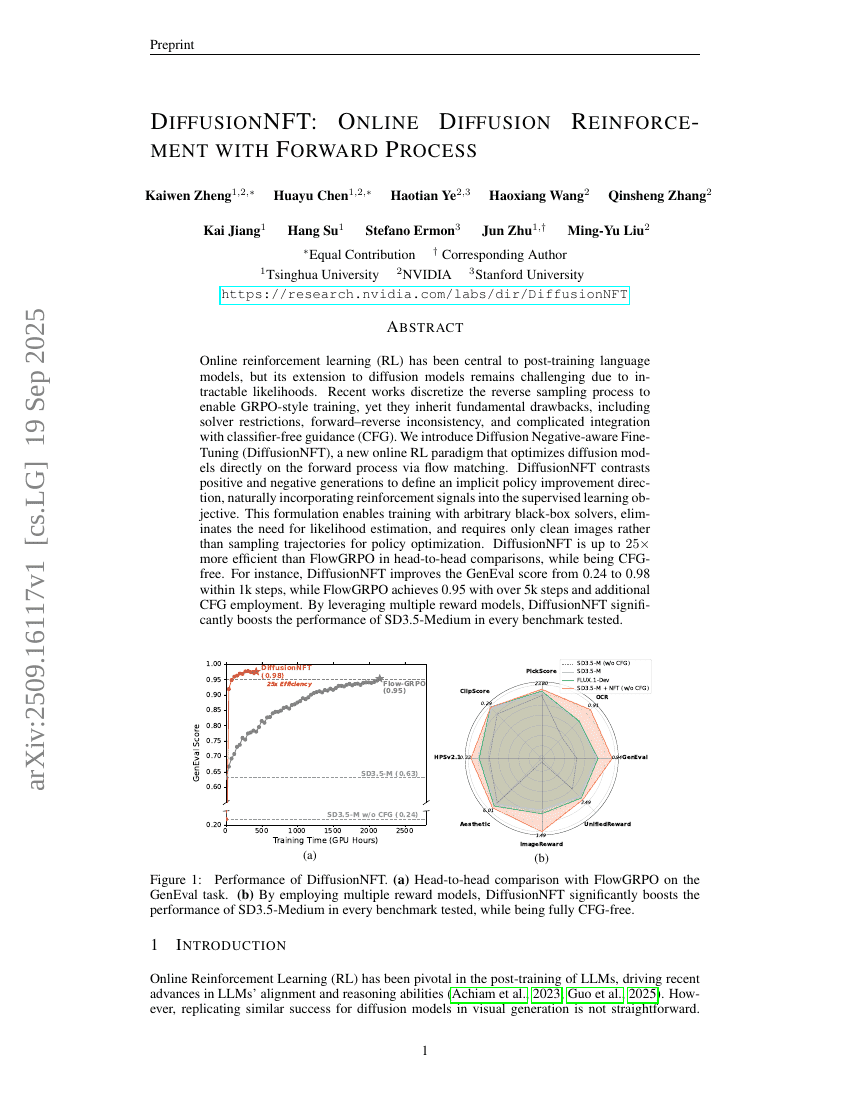
온라인 강화학습(RL)은 트레이닝 후 언어 모델의 핵심 요소로 자리 잡았으나, 확산 모델로의 확장은 계산이 불가능한 우도(likelihood)로 인해 여전히 도전 과제이다. 최근 연구들은 역방향 샘플링 과정을 이산화하여 GRPO 유사 학습을 가능하게 했지만, 해법기 제약, 전방-역방향 불일치, 그리고 분류기 자유 가이던스(CFG)와의 복잡한 통합이라는 근본적인 단점을 그대로 계승하고 있다. 본 연구에서는 흐름 매칭(flow matching)을 통해 전방 과정에서 직접 확산 모델을 최적화하는 새로운 온라인 RL 프레임워크인 '확산 음성 인식 미세조정(DiffusionNFT)'을 제안한다. DiffusionNFT는 긍정적 생성과 부정적 생성을 대비시켜 암묵적인 정책 개선 방향을 정의함으로써, 강화 신호를 감독 학습 목표에 자연스럽게 통합한다. 이 공식화는 임의의 블랙박스 해법기와 함께 학습이 가능하게 하며, 우도 추정이 필요 없고, 정책 최적화를 위해 샘플링 경로가 아닌 단순한 정제된 이미지만으로도 충분하다. 헤드 투 헤드 비교에서 DiffusionNFT는 FlowGRPO보다 최대 25배 더 효율적이며, CFG를 사용하지 않아도 된다. 예를 들어, DiffusionNFT는 1,000단계 내에서 GenEval 점수를 0.24에서 0.98로 향상시키지만, FlowGRPO는 5,000단계 이상의 학습과 추가적인 CFG 적용을 통해 0.95의 점수를 기록한다. 다양한 보상 모델을 활용함으로써, DiffusionNFT는 테스트된 모든 벤치마크에서 SD3.5-Medium의 성능을 크게 향상시켰다.