Command Palette
Search for a command to run...
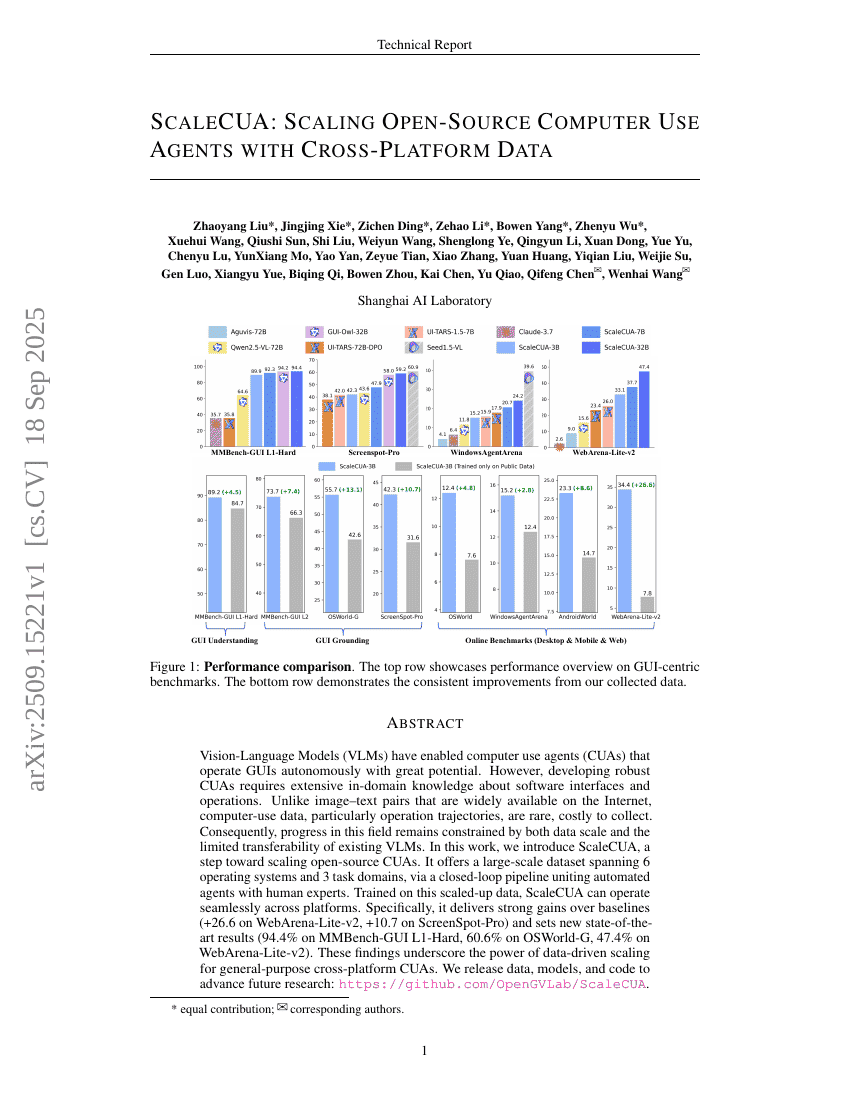
초록
시각-언어 모델(Vision-Language Models, VLMs)은 GUI를 자율적으로 운영할 수 있는 컴퓨터 사용 에이전트(Computer Use Agents, CUAs)의 가능성을 열었으며, 큰 잠재력을 보여주고 있으나, 대규모의 오픈소스 컴퓨터 사용 데이터와 기반 모델의 부족으로 인해 발전이 제한되고 있다. 본 연구에서는 오픈소스 CUAs의 확장 가능성을 향한 한 걸음으로, ScaleCUA를 제안한다. ScaleCUA는 자동화된 에이전트와 인간 전문가를 결합한 폐쇄형 루프 파이프라인을 통해 6개의 운영체제와 3개의 작업 영역을 아우르는 대규모 데이터셋을 구축한다. 이러한 확장된 데이터셋으로 훈련된 ScaleCUA는 다양한 플랫폼 간 원활한 운영이 가능하다. 구체적으로, 기존 베이스라인 대비 뚜렷한 성능 향상을 보이며 WebArena-Lite-v2에서 +26.6, ScreenSpot-Pro에서 +10.7의 성과를 기록했고, MMBench-GUI L1-Hard에서는 94.4%, OSWorld-G에서는 60.6%, WebArena-Lite-v2에서는 47.4%의 새로운 최고 성능을 달성했다. 이러한 결과는 일반 목적의 컴퓨터 사용 에이전트에 있어 데이터 기반 확장 전략의 강력한 효과를 입증한다. 본 연구는 향후 연구 발전을 위해 데이터, 모델, 코드를 공개할 예정이다. 자세한 내용은 다음 링크를 참조하시기 바랍니다: https://github.com/OpenGVLab/ScaleCUA.