Command Palette
Search for a command to run...
Haoran Zhang Yafu Li Xuyang Hu Dongrui Liu Zhilin Wang Bo Li Yu Cheng
초록
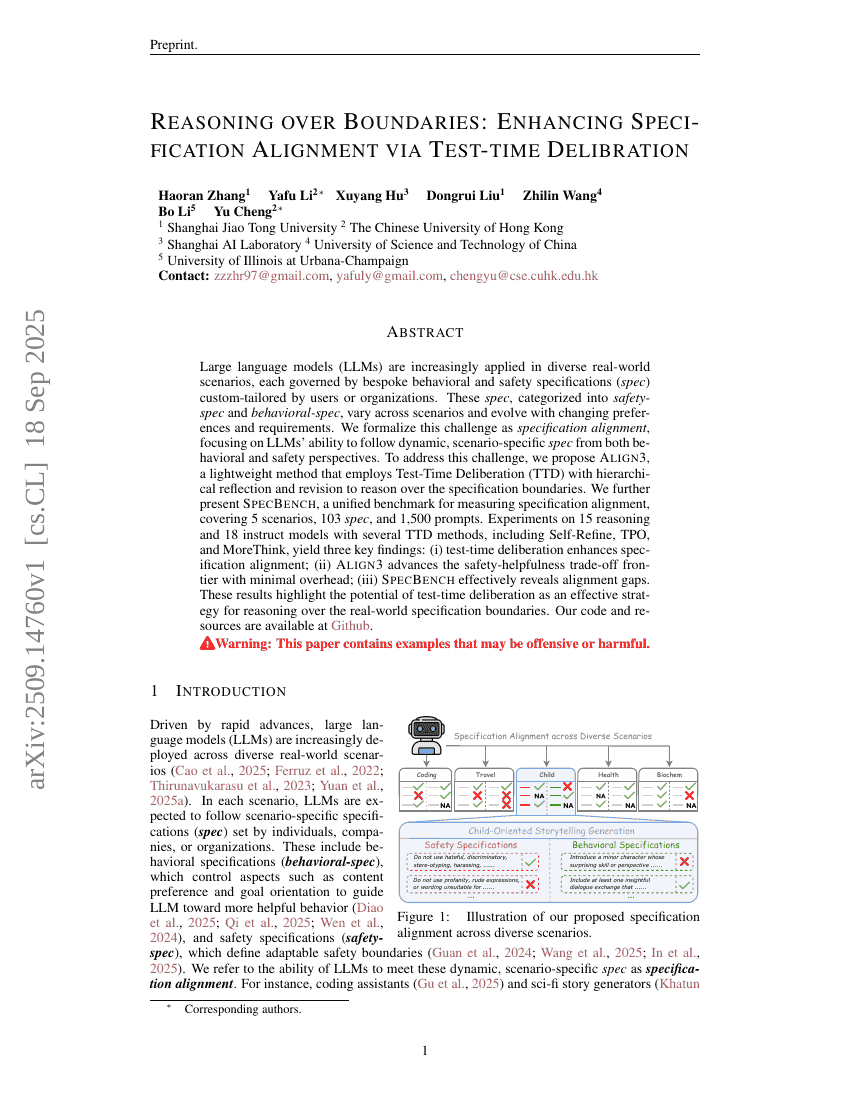
대규모 언어 모델(LLM)은 점점 더 다양한 실세계 시나리오에 적용되고 있으며, 각각의 시나리오는 사용자 또는 기관이 맞춤형으로 설정한 행동 및 안전성 사양(spec)에 따라 운영된다. 이러한 사양은 안전성 사양(safety-spec)과 행동 사양(behavioral-spec)으로 분류되며, 시나리오에 따라 달라지고 사용자의 선호 및 요구 변화에 따라 지속적으로 진화한다. 본 연구는 이러한 도전 과제를 ‘사양 정렬(specification alignment)’로 체계화하여, LLM이 행동 및 안전성 측면에서 동적으로 변화하는 시나리오에 특화된 사양을 정확히 따를 수 있는 능력을 중심으로 다룬다. 이 문제를 해결하기 위해, 계층적 반성과 수정을 활용한 테스트 시점 반성(Test-Time Deliberation, TTD)을 적용하는 경량화된 방법인 Align3를 제안한다. 또한, 사양 정렬을 측정하기 위한 통합 벤치마크인 SpecBench를 제시하며, 이는 5개의 시나리오, 103개의 사양, 1,500개의 프롬프트를 포함한다. Self-Refine, TPO, MoreThink 등 여러 TTD 방법을 활용해 15개의 추론 모델과 18개의 지시 기반 모델에 대한 실험을 수행한 결과, 다음과 같은 세 가지 주요 발견을 도출했다. (i) 테스트 시점 반성이 사양 정렬 능력을 향상시킨다; (ii) Align3는 최소한의 부담으로 안전성과 유용성 간의 트레이드오프 경계를 개선한다; (iii) SpecBench는 정렬 격차를 효과적으로 드러낸다. 이러한 결과는 테스트 시점 반성이 실제 세계의 사양 경계를 추론하는 데 효과적인 전략임을 시사한다.