Command Palette
Search for a command to run...
초록
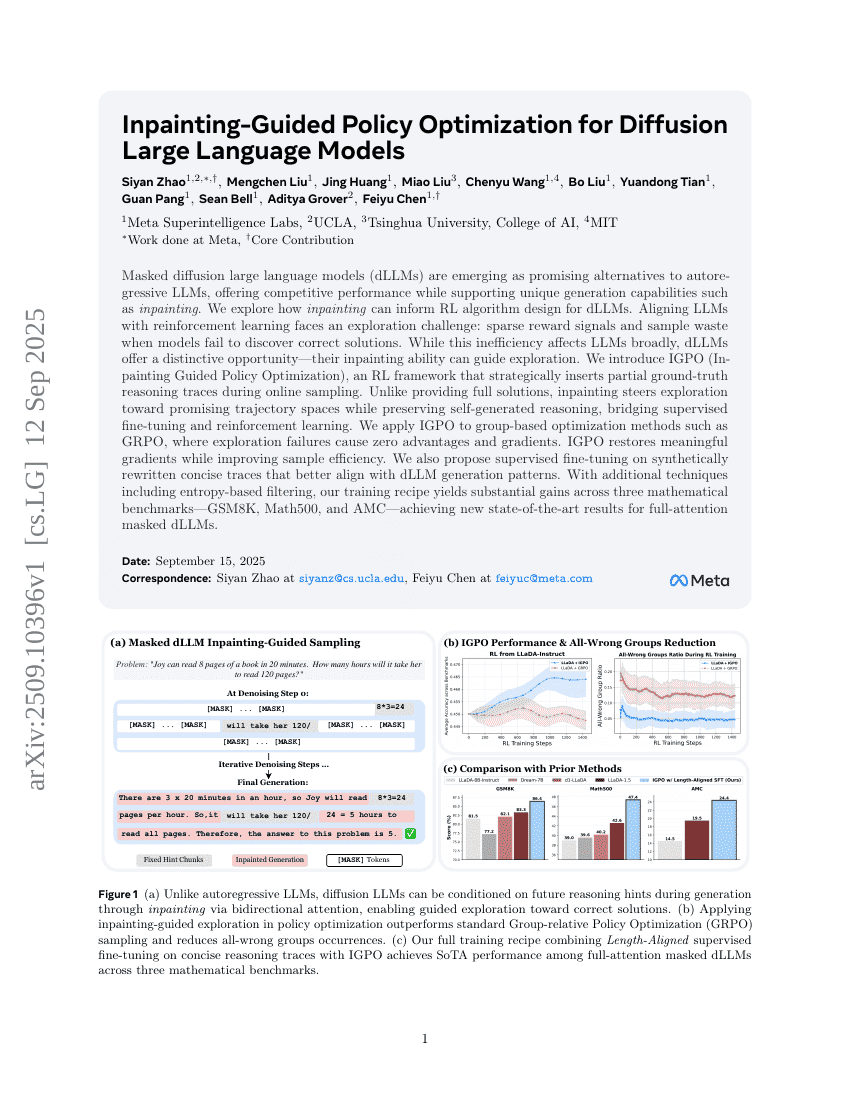
마스킹된 확산 대규모 언어 모델(masked diffusion large language models, dLLMs)는 자동회귀형 LLMs에 대한 유망한 대안으로 부상하고 있으며, 입체화(inkpainting)와 같은 독특한 생성 기능을 지원하면서도 경쟁력 있는 성능을 제공한다. 본 연구는 입체화 기능이 dLLM에 대한 강화학습(RL) 알고리즘 설계에 어떻게 기여할 수 있는지 탐구한다. LLMs를 강화학습과 연계하는 과정에서 직면하는 주요 과제는 탐색의 어려움이다. 모델이 정답을 탐색하지 못할 경우 보상 신호가 희박해지고 샘플이 낭비되며, 이는 LLMs 전반에 걸쳐 공통된 문제이지만, dLLMs는 특별한 기회를 제공한다. 바로 입체화 기능을 통해 탐색을 안내할 수 있다는 점이다. 본 연구에서는 온라인 샘플링 과정에서 부분적인 정답 추론 흐름(ground-truth reasoning traces)을 전략적으로 삽입하는 RL 프레임워크인 IGPO(Inpainting Guided Policy Optimization)를 제안한다. 완전한 해답을 제공하는 대신, 입체화는 모델이 탐색을 보다 유망한 추론 경로 공간으로 유도하면서도 자가 생성된 추론을 유지함으로써, 지도 학습 기반 미세조정(supervised fine-tuning)과 강화학습 간의 간극을 메운다. 이 방법은 GRPO와 같은 그룹 기반 최적화 기법에 적용되며, 이 경우 탐색 실패로 인해 보상이 0이 되고 기울기(gradient)가 소실되는 문제를 해결한다. IGPO는 의미 있는 기울기를 복원하면서도 샘플 효율성을 높인다. 또한, dLLM의 생성 패턴과 더 잘 부합하는 간결한 추론 흐름을 합성적으로 재작성하여 지도 학습을 수행하는 방식을 제안한다. 엔트로피 기반 필터링과 같은 보조 기술을 추가로 활용함으로써, 본 연구의 훈련 전략은 세 가지 수학 벤치마크(GSM8K, Math500, AMC)에서 뚜렷한 성능 향상을 이끌어내며, 전체 어텐션을 사용하는 마스킹된 dLLM의 경우 새로운 최고 성능(SOTA)을 달성하였다.