Command Palette
Search for a command to run...
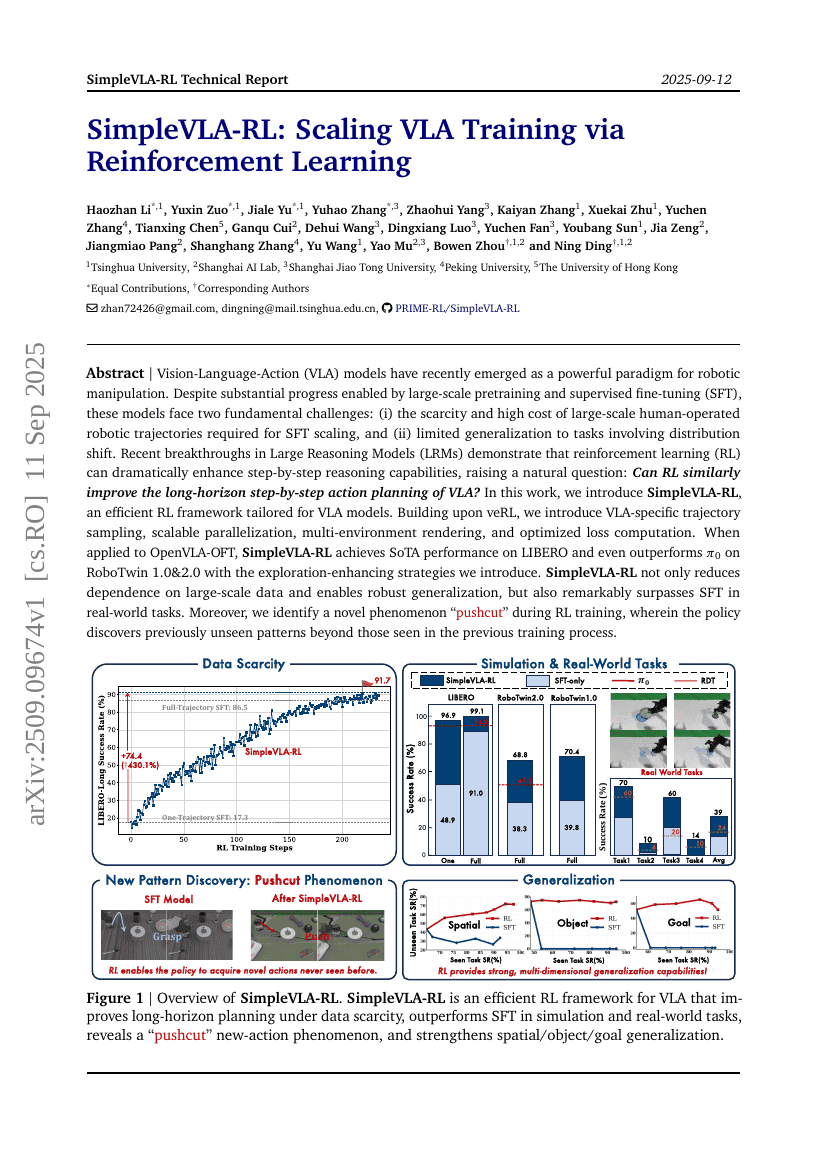
초록
시각-언어-행동(Vision-Language-Action, VLA) 모델은 최근 로봇 조작 분야에서 강력한 패러다임으로 부상하고 있다. 대규모 사전학습과 감독형 미세조정(Supervised Fine-Tuning, SFT)을 통해 상당한 진전이 이루어졌음에도 불구하고, 이러한 모델은 두 가지 근본적인 과제에 직면해 있다. 첫째, SFT의 확장에 필수적인 대규모 인간 조작 로봇 경로 데이터의 희소성과 높은 수집 비용이며, 둘째, 분포 변화(distribution shift)를 포함하는 과제에 대한 제한된 일반화 능력이다. 최근 대규모 추론 모델(Large Reasoning Models, LRMs)에서의 돌파구는 강화학습(Reinforcement Learning, RL)이 단계별 추론 능력을 크게 향상시킬 수 있음을 보여주며, 자연스럽게 다음과 같은 질문을 제기한다: RL은 VLA 모델의 장기적 단계별 행동 계획 능력에도 유사한 향상을 가져올 수 있는가? 본 연구에서는 VLA 모델에 특화된 효율적인 강화학습 프레임워크인 SimpleVLA-RL을 제안한다. veRL 기반으로, VLA에 적합한 경로 샘플링, 확장 가능한 병렬화, 다중 환경 렌더링, 최적화된 손실 계산 기법을 도입하였다. OpenVLA-OFT에 적용했을 때, SimpleVLA-RL은 LIBERO에서 최고 성능(SoTA)을 달성하였으며, 제안한 탐색 증진 전략을 활용해 RoboTwin 1.0 및 2.0에서도 pi_0를 상회하는 성능을 기록하였다. SimpleVLA-RL은 대규모 데이터에 대한 의존도를 줄이고 견고한 일반화 능력을 제공할 뿐만 아니라, 실제 환경에서 SFT보다 뚜렷하게 뛰어난 성능을 보였다. 더불어, RL 학습 과정에서 기존 학습 과정에서 관측되지 않은 새로운 패턴을 탐지하는 새로운 현상인 ‘pushcut’을 발견하였다. GitHub: https://github.com/PRIME-RL/SimpleVLA-RL