Command Palette
Search for a command to run...
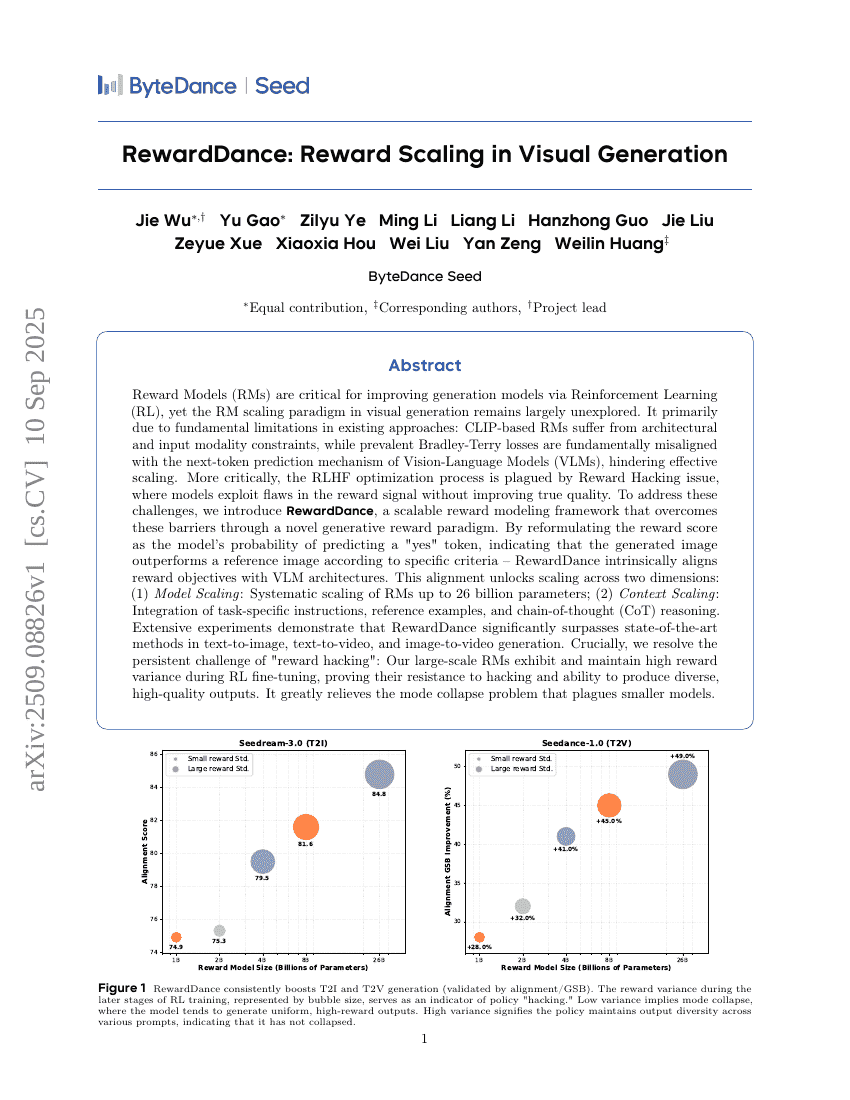
초록
보상 모델(Reward Models, RMs)은 강화학습(Reinforcement Learning, RL)을 통해 생성 모델의 성능을 향상시키는 데 핵심적인 역할을 하지만, 시각 생성 분야에서의 RMs 확장 전략은 여전히 거의 탐색되지 않은 상태이다. 이는 기존 접근 방식의 근본적인 한계에 기인한다. CLIP 기반 RMs는 아키텍처적 제약과 입력 모달리티의 제약을 겪는 반면, 일반적으로 사용되는 Bradley-Terry 손실 함수는 시각-언어 모델(Vision-Language Models, VLMs)의 다음 토큰 예측 메커니즘과 본질적으로 부합하지 않아 효과적인 확장이 어렵다. 더욱 심각한 문제는 RLHF 최적화 과정에서 발생하는 '보상 해킹(Reward Hacking)' 현상이다. 이는 모델이 보상 신호의 결함을 악용하여 진정한 품질 향상 없이 보상 값을 높이는 방식으로 작동하는 현상으로, 학습의 신뢰성을 저해한다. 이러한 문제를 해결하기 위해, 우리는 새로운 생성형 보상 파라다임을 통해 이러한 장벽을 극복하는 확장 가능한 보상 모델링 프레임워크인 RewardDance를 제안한다. RewardDance는 보상 점수를 생성된 이미지가 특정 기준에 따라 참조 이미지보다 우수하다는 것을 나타내는 '예(yes)' 토큰을 모델이 예측할 확률로 재정의함으로써, 보상 목표를 VLM 아키텍처와 본질적으로 일치시킨다. 이러한 일치는 두 가지 차원에서의 확장 가능성을 열어준다. (1) 모델 확장: 최대 260억 파라미터에 이르는 체계적인 RMs 확장; (2) 컨텍스트 확장: 작업에 특화된 지시어, 참조 예시, 사고의 흐름(Chain-of-Thought, CoT) 추론을 통합하는 방식. 광범위한 실험을 통해 RewardDance가 텍스트-이미지, 텍스트-비디오, 이미지-비디오 생성 분야에서 기존 최고 수준의 방법들을 크게 능가함을 입증하였다. 특히, 오랫동안 해결되지 않았던 '보상 해킹' 문제를 극복했다. 대규모 RMs는 RL 미세조정 과정에서 높은 보상 변동성을 유지함으로써, 해킹에 대한 저항력을 입증하며 다양한 고품질 출력을 지속적으로 생성할 수 있음을 보였다. 이는 소규모 모델에서 흔히 발생하는 모드 붕괴(mode collapse) 문제를 크게 완화하는 데 기여한다.