Command Palette
Search for a command to run...
Haoyu Dong Pengkun Zhang Mingzhe Lu Yanzhen Shen Guolin Ke
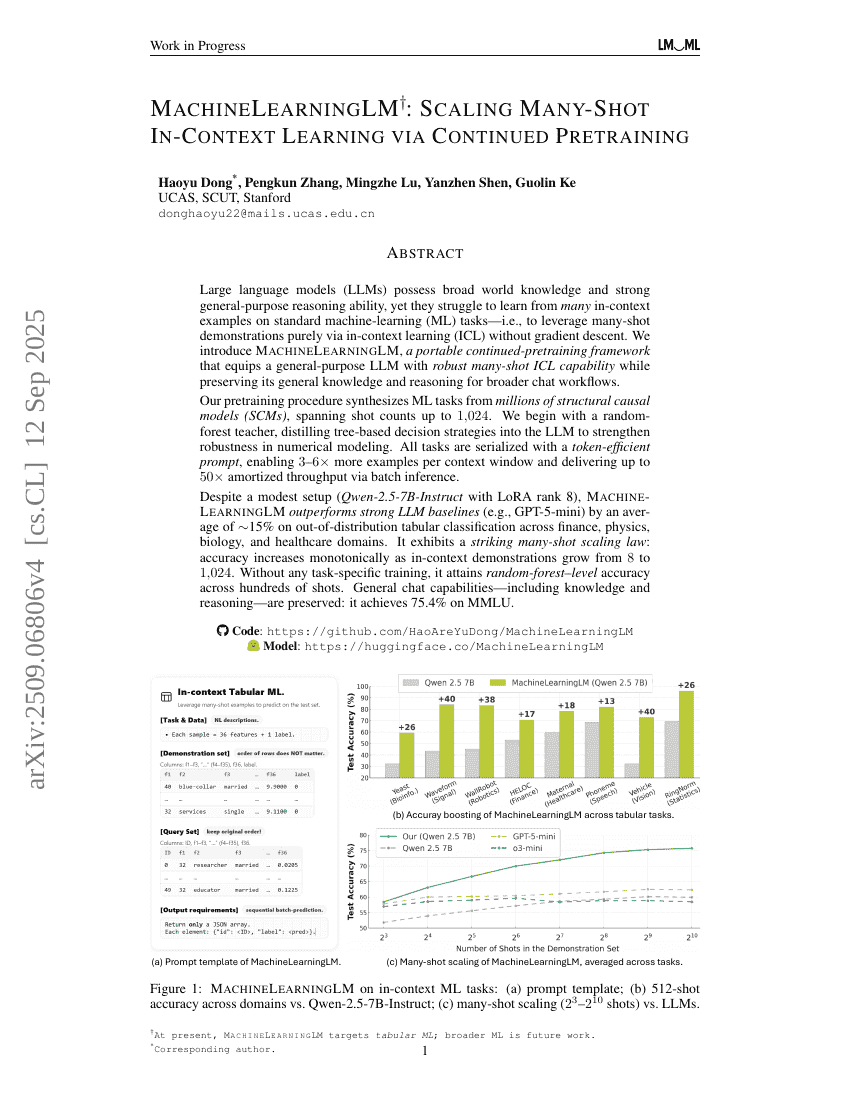
초록
대규모 언어 모델(LLM)은 광범위한 세계 지식과 강력한 일반적 추론 능력을 보유하고 있으나, 표준 기계학습(ML) 과제에서 많은 컨텍스트 내 예시를 통해 학습하는 데 어려움을 겪는다. 즉, 경사 하강법 없이 순수하게 컨텍스트 내 학습(ICL)을 통해 다수의 예시(많은 샷)를 활용하는 데 한계가 있다. 본 연구에서는 일반 목적 LLM에 강력한 컨텍스트 내 ML 능력을 부여하면서도, 보편적 지식과 추론 능력을 유지할 수 있도록 설계된 이식 가능한 지속적 사전 훈련 프레임워크인 MachineLearningLM을 제안한다. 이는 더 넓은 대화 워크플로우에서의 활용을 가능하게 한다.우리의 사전 훈련 절차는 수백만 개의 구조적 인과 모델(SCM)로부터 ML 과제를 합성하여, 최대 1,024개의 샷까지의 다양한 샷 수를 커버한다. 초기에는 랜덤 포레스트 기반의 교사 모델을 사용하여 트리 기반의 결정 전략을 LLM에 정제함으로써 수치 모델링에 대한 강건성을 강화한다. 모든 과제는 토큰 효율적인 프롬프트로 직렬화되어, 컨텍스트 창당 최대 3배에서 6배의 예시를 더 포함할 수 있으며, 배치 추론을 통해 최대 50배의 평균 처리량 향상을 달성한다.소규모 설정(LoRA 랭크 8을 갖춘 Qwen-2.5-7B-Instruct)에도 불구하고, MachineLearningLM은 금융, 물리학, 생물학, 의료 등 다양한 도메인에서 분포 외(tabular classification) 과제에 대해 강력한 LLM 기준 모델(예: GPT-5-mini)보다 평균적으로 약 15% 높은 성능을 기록한다. 특히, 많은 샷 스케일링 법칙이 뚜렷하게 나타나며, 컨텍스트 내 예시 수가 8에서 1,024로 증가함에 따라 정확도가 단조 증가하는 경향을 보인다. 어떠한 과제 특화 훈련 없이도 수백 개의 샷에서 랜덤 포레스트 수준의 정확도를 달성한다. 또한 일반적인 대화 능력, 즉 지식과 추론 능력은 그대로 유지되며, MMLU에서 75.4%의 성능을 기록한다.