Command Palette
Search for a command to run...
Xingxuan Zhang Gang Ren Han Yu Hao Yuan Hui Wang et al
초록
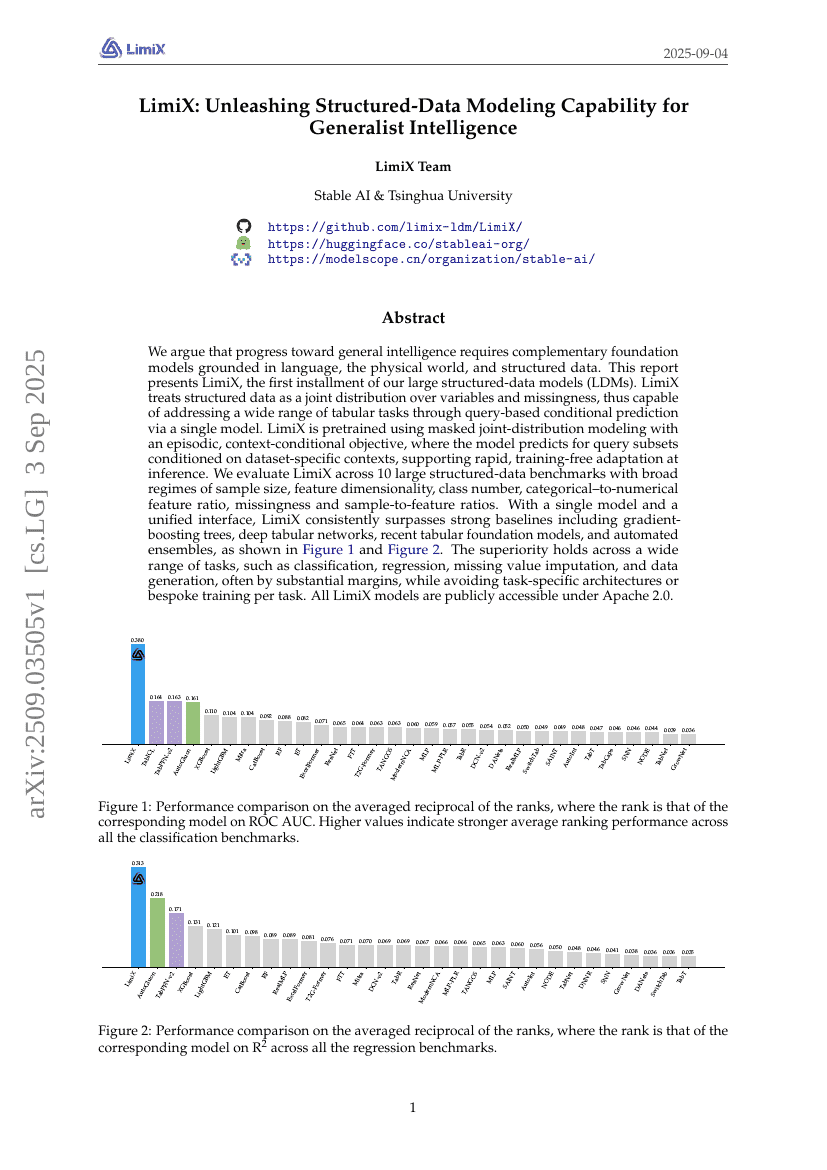
일반지능에로의 진전을 위해서는 언어, 물리 세계, 구조화된 데이터를 기반으로 하는 보완적인 기초 모델이 필요하다고 주장한다. 본 보고서는 대규모 구조화된 데이터 모델(LDMs)의 첫 번째 버전인 LimiX를 제시한다. LimiX는 구조화된 데이터를 변수와 누락 여부에 대한 공동 분포로 취급함으로써, 단일 모델을 통해 질의 기반 조건부 예측 방식으로 다양한 표 형식(Tabular) 작업을 처리할 수 있다. LimiX는 에피소드 기반의 맥락 조건부 목표함수를 사용하여 마스크된 공동분포 모델링 방식으로 사전학습되며, 데이터셋 고유의 맥락을 기반으로 질의 서브셋에 대한 예측을 수행함으로써 추론 시 빠르고 학습 없이도 적응이 가능하다. 우리는 표본 크기, 특징 차원 수, 클래스 수, 범주형 대 수치형 특징 비율, 누락 비율, 표본 대 특징 비율 등 다양한 범위를 가진 10개의 대규모 구조화된 데이터 벤치마크에서 LimiX를 평가하였다. 단일 모델과 통일된 인터페이스를 통해, 그림 1과 그림 2에서 보듯이, 기울기 부스팅 트리, 딥 표 형식 네트워크, 최근의 표 형식 기초 모델, 자동화된 앙상블 등 강력한 기준 모델들을 일관되게 상회한다. 이 우수성은 분류, 회귀, 결측치 보정, 데이터 생성 등 다양한 작업에서 뚜렷한 성능 차이로 나타나며, 작업별 특화된 아키텍처나 각 작업에 맞춘 맞춤형 학습 없이도 유지된다. 모든 LimiX 모델은 Apache 2.0 라이선스 하에 공개되어 누구나 접근 가능하다.