Command Palette
Search for a command to run...
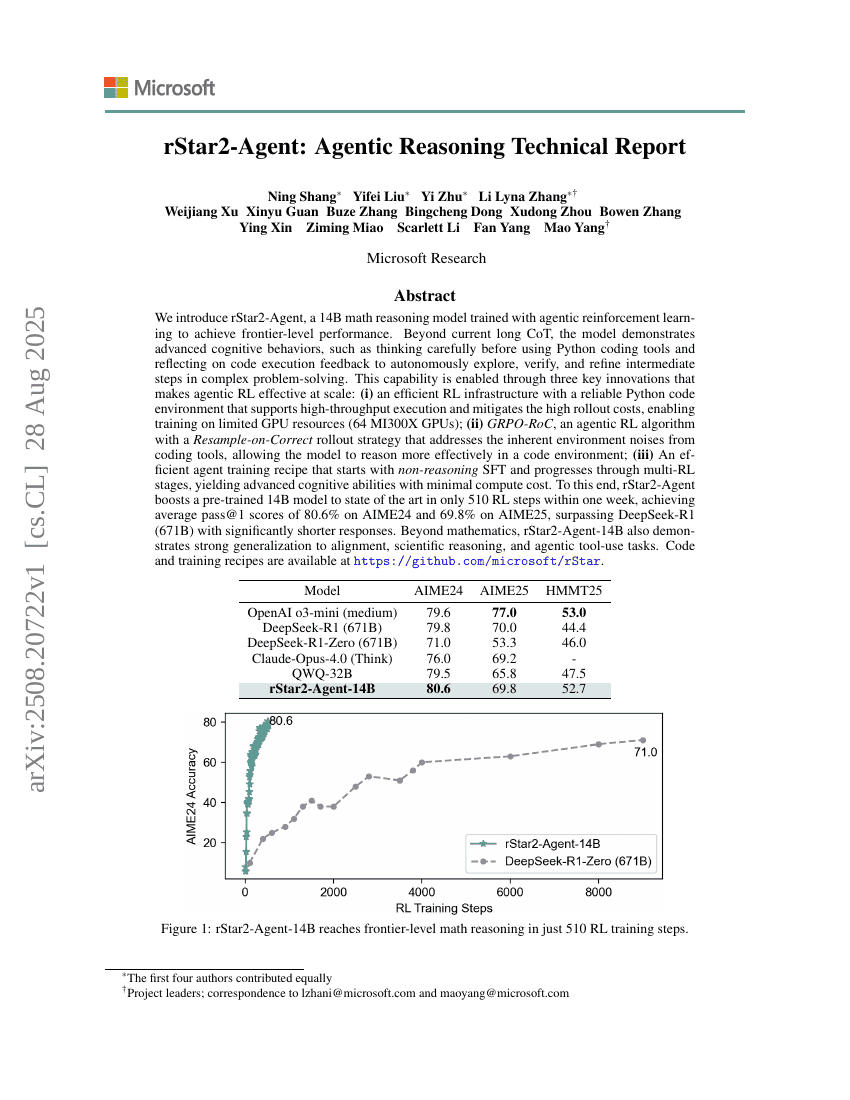
초록
우리는 에이전트 기반 강화학습을 통해 훈련된 14B 규모의 수학 추론 모델인 rStar2-Agent를 소개합니다. 이 모델은 최첨단 수준의 성능을 달성하며, 현재의 긴 사고 과정(Long CoT)을 넘어서는 고도화된 인지적 행동을 보여줍니다. 예를 들어, 파이썬 코드 도구를 사용하기 전에 신중하게 사고하고, 코드 실행 결과 피드백을 반영하여 복잡한 문제 해결 과정에서 중간 단계를 자율적으로 탐색, 검증 및 개선하는 능력을 갖추고 있습니다. 이러한 능력은 세 가지 핵심 기술 혁신을 통해 가능해졌으며, 이는 에이전트 기반 강화학습을 대규모로 효과적으로 적용할 수 있도록 합니다. (i) 고성능 파이썬 코드 환경을 지원하는 효율적인 강화학습 인프라로, 높은 처리량 실행을 가능하게 하며, 높은 롤아웃 비용을 완화함으로써 제한된 GPU 자원(64개의 MI300X GPU)에서도 훈련이 가능하게 합니다. (ii) 코드 도구에서 발생하는 내재적 환경 노이즈를 해결하기 위한 ‘정답 재표본화(Resample-on-Correct)’ 전략을 채택한 에이전트 기반 강화학습 알고리즘인 GRPO-RoC입니다. 이는 코드 환경에서 모델이 더욱 효과적으로 추론할 수 있도록 합니다. (iii) 추론이 없는 SFT(Supervised Fine-Tuning)로 시작하여 다단계 강화학습을 거치는 효율적인 에이전트 훈련 방법론으로, 최소한의 계산 자원 소모로 고도화된 인지 능력을 얻을 수 있습니다. 이러한 기술들을 바탕으로 rStar2-Agent는 단 1주일 내에 510회의 강화학습 단계만으로 사전 훈련된 14B 모델을 최신 기술 수준으로 끌어올렸으며, AIME24에서 평균 pass@1 점수 80.6%, AIME25에서는 69.8%를 기록하여, 훨씬 더 짧은 응답 길이로 671B 규모의 DeepSeek-R1을 능가했습니다. 수학 외에도 rStar2-Agent-14B는 일치성(Alignment), 과학적 추론, 에이전트 기반 도구 사용 등 다양한 작업에 대해 뛰어난 일반화 능력을 보여줍니다. 코드 및 훈련 방법론은 https://github.com/microsoft/rStar 에서 공개되어 있습니다.