Command Palette
Search for a command to run...
Sixun Dong Juhua Hu Mian Zhang Ming Yin Yanjie Fu Qi Qian
초록
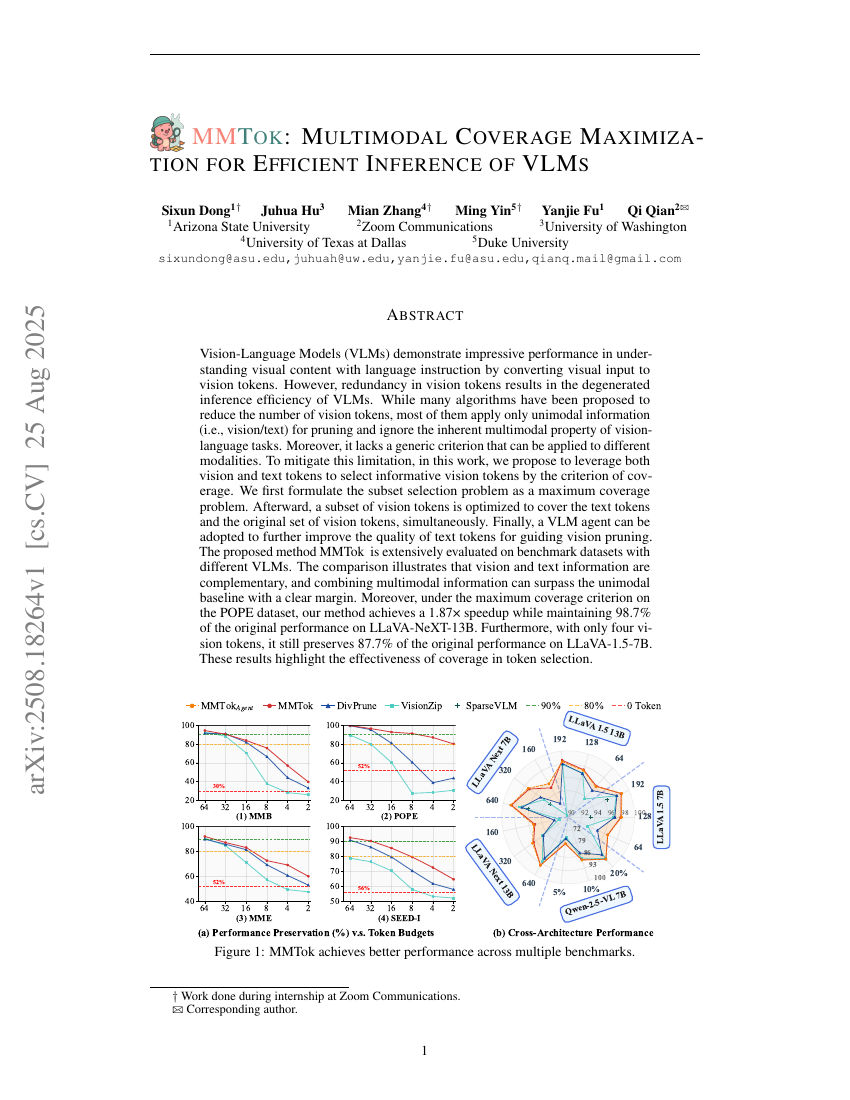
시각-언어 모델(Vision-Language Models, VLMs)은 시각 입력을 시각 토큰으로 변환함으로써 언어 지시에 따라 시각 콘텐츠를 효과적으로 이해하는 데 뛰어난 성능을 보여준다. 그러나 시각 토큰 내부의 중복성은 VLM의 추론 효율성을 저하시키는 원인이 된다. 많은 알고리즘이 시각 토큰 수를 줄이기 위해 제안되었지만, 대부분은 단일 모달 정보(즉, 시각/텍스트)만을 이용하여 토큰을 자르는 방식을 채택하고 있으며, 시각-언어 작업의 본질적인 다중 모달 특성을 간과하고 있다. 더불어, 다양한 모달에 적용 가능한 일반적인 평가 기준이 부족한 실정이다. 이러한 한계를 해결하기 위해 본 연구에서는 커버리지(coverage) 기준을 활용하여 시각 토큰과 텍스트 토큰을 함께 고려함으로써 정보량이 풍부한 시각 토큰을 선택하는 방법을 제안한다. 먼저, 부분 집합 선택 문제를 최대 커버리지 문제로 수식화한다. 이후, 최적화된 시각 토큰 부분집합이 텍스트 토큰과 원래의 시각 토큰 전체 집합을 동시에 커버하도록 한다. 마지막으로, VLM 에이전트를 도입하여 텍스트 토큰의 품질을 추가로 향상시켜 시각 토큰 절단을 보다 효과적으로 유도한다. 제안한 방법 MMTok은 다양한 VLM을 사용한 벤치마크 데이터셋에서 광범위하게 평가되었다. 실험 결과에 따르면, 시각 정보와 텍스트 정보는 상호 보완적이며, 다중 모달 정보를 결합하면 단일 모달 기반의 기준보다 명확한 성능 우위를 보인다. 특히 POPE 데이터셋에서 최대 커버리지 기준을 적용했을 때, LLaVA-NeXT-13B 모델은 원래 성능의 98.7%를 유지하면서 1.87배의 속도 향상을 달성하였다. 또한, 시각 토큰을 단 4개로 제한하더라도 LLaVA-1.5-7B 모델은 원래 성능의 87.7%를 유지할 수 있었다. 이러한 결과는 토큰 선택 과정에서 커버리지 개념의 효과성을 입증한다.