Command Palette
Search for a command to run...
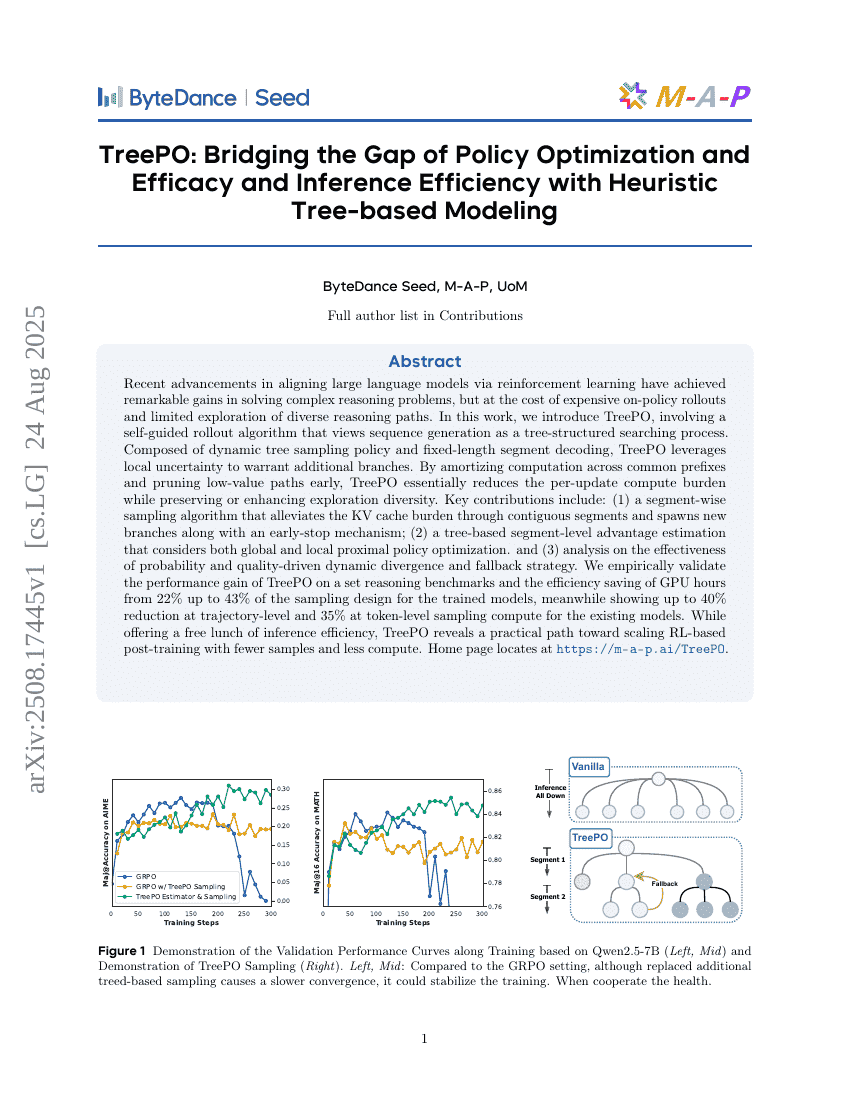
초록
최근 강화학습을 통한 대규모 언어모델의 정렬 기술은 복잡한 추론 문제 해결에서 놀라운 성과를 거두었으나, 높은 온폴리시(On-policy) 롤아웃 비용과 다양한 추론 경로 탐색의 제한이라는 비용을 수반해 왔다. 본 연구에서는 시퀀스 생성을 트리 구조의 탐색 과정으로 간주하는 자기주도적 롤아웃 알고리즘을 도입한 TreePO를 제안한다. TreePO는 동적 트리 샘플링 정책과 고정 길이 세그먼트 디코딩으로 구성되어 있으며, 국소적 불확실성을 활용해 추가적인 분기 경로를 생성한다. 공통 접두사에 대한 계산을 분산 처리하고, 가치가 낮은 경로를 조기에 제거함으로써, TreePO는 업데이트당 계산 부담을 극적으로 줄이면서도 탐색의 다양성은 유지하거나 향상시킨다. 본 연구의 주요 기여는 다음과 같다: (1) 연속적인 세그먼트를 통해 KV 캐시 부담을 완화하고, 조기 중단 메커니즘과 함께 새로운 분기를 생성하는 세그먼트 단위 샘플링 알고리즘; (2) 전역적 및 국소적 근접 정책 최적화를 고려한 트리 기반 세그먼트 수준의 이득 추정; (3) 확률 기반과 품질 기반 동적 분기 및 백오프 전략의 효과성에 대한 분석. 실증적으로 TreePO는 여러 추론 벤치마크에서 성능 향상을 입증하였으며, 학습된 모델의 샘플링 설계에 대해 GPU 시간을 22%에서 최대 43%까지 절약함을 확인하였다. 또한 기존 모델에 대해 궤적 수준에서 최대 40%, 토큰 수준에서 최대 35%의 샘플링 계산량 감소를 보였다. TreePO는 추론 효율성의 '무료 점심'을 제공함과 동시에, 더 적은 샘플과 낮은 계산량으로 강화학습 기반 후학습을 확장하는 실용적인 길을 제시한다. 홈페이지는 https://m-a-p.ai/TreePO 에서 확인할 수 있다.