Command Palette
Search for a command to run...
Zengzhi Wang Fan Zhou Xuefeng Li Pengfei Liu
초록
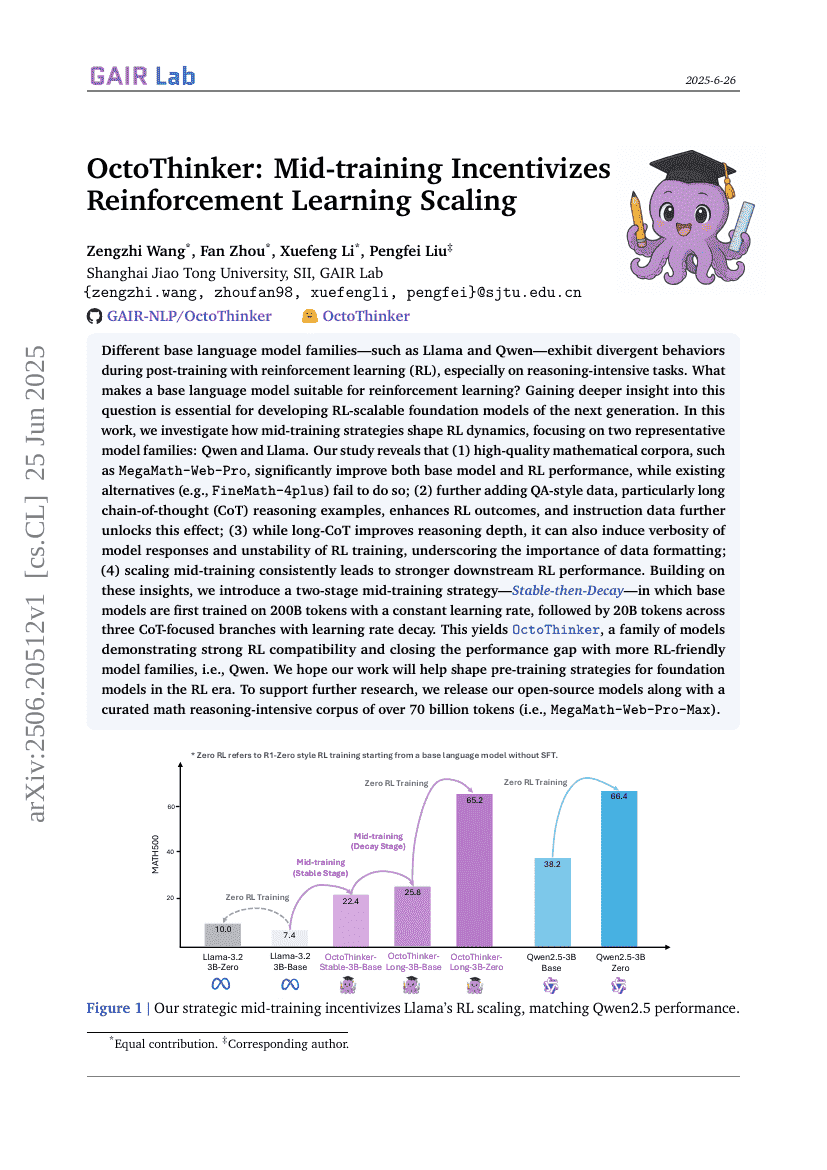
다른 기반 언어 모델 가족들, 예를 들어 Llama와 Qwen은 강화 학습(RL) 후 훈련 과정에서 서로 다른 행동을 보입니다. 특히 추론이 요구되는 작업에서는 이러한 차이가 두드러집니다. 어떤 기반 언어 모델이 강화 학습에 적합한지를 이해하는 것은 다음 세대의 RL 확장 가능한 기초 모델을 개발하는 데 필수적입니다. 본 연구에서는 중간 훈련 전략이 RL 동역학에 어떻게 영향을 미치는지 조사하며, 이를 위해 Qwen과 Llama라는 두 가지 대표적인 모델 가족에 집중하였습니다.본 연구 결과는 다음과 같습니다: (1) MegaMath-Web-Pro와 같은 고품질 수학 코퍼스는 기반 모델과 RL 성능을 크게 향상시키지만, 기존의 대안(예: FineMath-4plus)들은 그러한 효과를 나타내지 못합니다; (2) QA 형식의 데이터, 특히 긴 사고 과정(CoT) 추론 예제를 추가하면 RL 결과가 개선되며, 지시문 데이터는 이 효과를 더욱 강화합니다; (3) 긴 CoT는 추론 깊이를 개선하지만, 동시에 모델 응답의 장황함과 RL 훈련의 불안정성을 유발할 수 있어 데이터 포맷팅의 중요성을 강조합니다; (4) 중간 훈련의 스케일링은 일관성 있게 하류 RL 성능을 향상시킵니다.이러한 통찰력을 바탕으로, 우리는 Stable-then-Decay라는 두 단계 중간 훈련 전략을 제안합니다. 이 전략은 먼저 2000억 개의 토큰으로 일정한 학습률로 기반 모델을 훈련시키고, 그 다음 200억 개의 토큰으로 세 가지 CoT 중심 분기에서 학습률 감소를 적용하여 추가로 훈련시키는 방식입니다. 이를 통해 OctoThinker라는 모델 가족을 생성하였으며, 이 모델들은 강력한 RL 호환성을 보여주며 더 많은 RL 친화적인 모델 가족인 Qwen과의 성능 격차를 좁혔습니다.우리는 본 연구가 RL 시대의 기초 모델 사전 훈련 전략을 설계하는 데 도움이 되기를 바랍니다. 또한 후속 연구를 지원하기 위해 700억 개 이상의 토큰으로 구성된 수학 추론 집약형 코퍼스(MegaMath-Web-Pro-Max)와 함께 오픈 소스 모델들을 공개합니다.