Command Palette
Search for a command to run...
초록
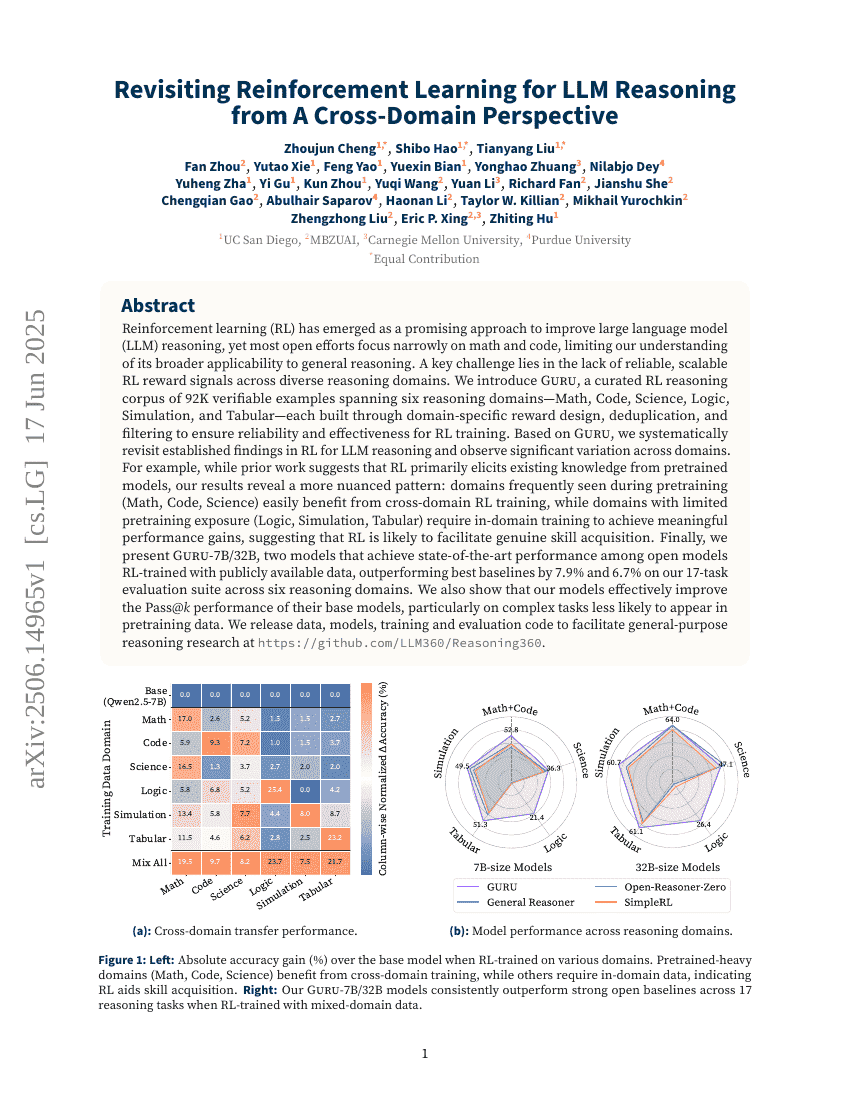
강화 학습(RL)은 대형 언어 모델(LLM)의 추론 능력을 향상시키는 유망한 접근 방식으로 부각되고 있지만, 대부분의 공개된 연구는 수학과 코드에만 국한되어 있어 일반적인 추론에 대한 그 폭넓은 적용 가능성에 대한 이해를 제한하고 있습니다. 주요 과제 중 하나는 다양한 추론 영역에서 신뢰성 있고 확장 가능한 RL 보상 신호를 확보하는 데 있습니다. 우리는 6개의 추론 영역(수학, 코드, 과학, 논리, 시뮬레이션, 표 형식 데이터)을 아우르는 92,000개의 검증 가능한 예제로 구성된 정리된 RL 추론 코퍼스인 Guru를 소개합니다. 각 영역은 도메인 특화 보상 설계, 중복 제거 및 필터링을 통해 RL 학습에 필요한 신뢰성과 효과성을 보장하기 위해 구축되었습니다. Guru를 기반으로 하여, 우리는 LLM 추론에서 이미 확립된 RL 관련 연구 결과들을 체계적으로 재검토하고 영역 간 상당한 차이점을 관찰하였습니다. 예를 들어, 이전 연구에서는 RL이 주로 사전 학습된 모델로부터 기존 지식을 유도한다는 점을 강조하였지만, 우리의 결과는 더 복잡한 패턴을 드러냅니다: 사전 학습 단계에서 자주 등장하는 영역(수학, 코드, 과학)은 다른 영역 간의 RL 학습으로 쉽게 혜택을 받지만, 사전 학습 노출이 제한적인 영역(논리, 시뮬레이션, 표 형식 데이터)은 의미 있는 성능 향상을 위해서 해당 도메인 내에서의 학습이 필요함을 나타냅니다. 이는 RL이 실제 기술 습득을 촉진할 가능성이 있음을 시사합니다. 마지막으로, 공개 데이터로 RL 학습된 모델 중 최고 성능을 달성한 두 개의 모델인 Guru-7B와 Guru-32B를 제시합니다. 이들 모델은 6개의 추론 영역에서 17가지 평가 작업을 수행한 결과에서 기존 베이스라인보다 각각 7.9%와 6.7% 우위를 보였습니다. 또한 우리의 모델들이 특히 사전 학습 데이터에 적게 포함되는 복잡한 작업에서 기반 모델들의 Pass@k 성능을 효과적으로 개선함을 확인하였습니다. 일반 목적 추론 연구를 지원하기 위해 데이터, 모델 및 학습 및 평가 코드를 다음 URL에서 공개합니다: this https URL