Command Palette
Search for a command to run...
Adam Tauman Kalai Yael Tauman Kalai Or Zamir
초록
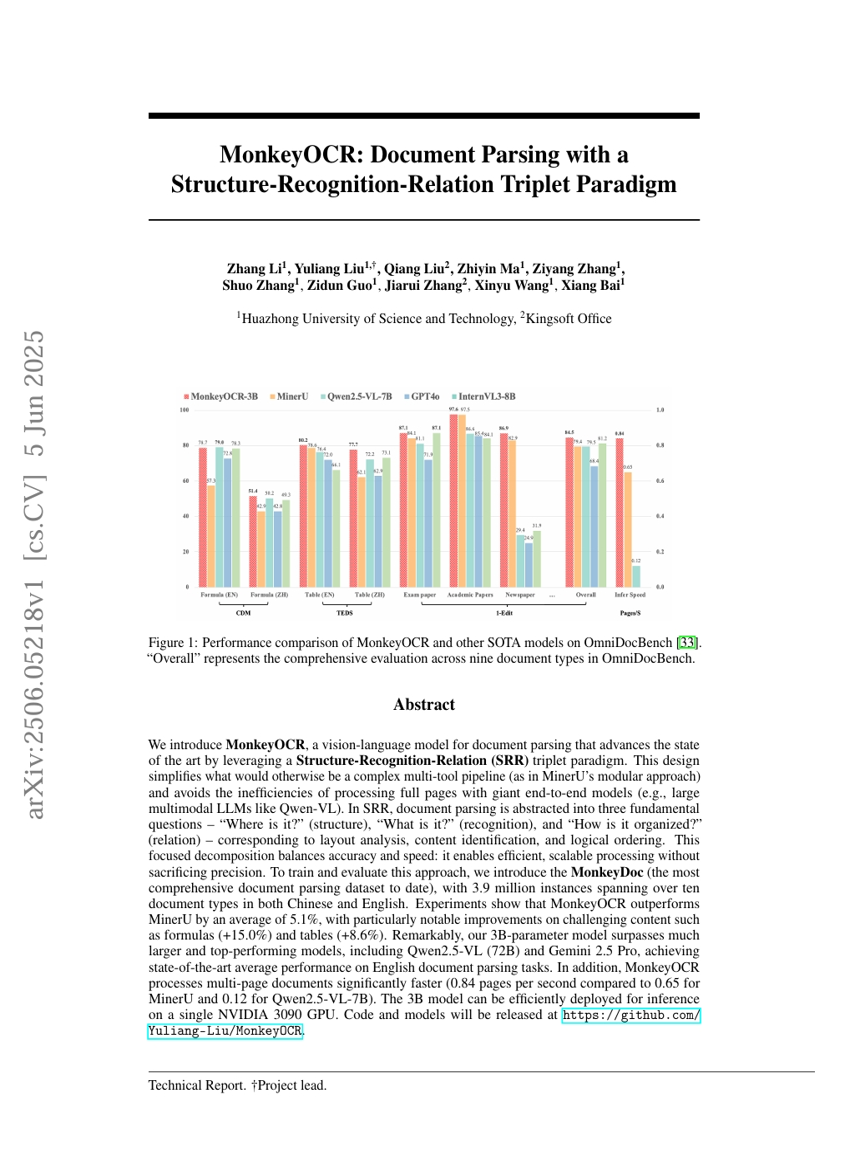
우리는 구조 인식 관계(SRR: Structure-Recognition-Relation) 삼중주 패러다임을 활용하여 문서 구문 분석 분야의 최신 기술을 선도하는 비전-언어 모델인 MonkeyOCR를 소개한다. 이 설계는 MinerU의 모듈형 접근 방식에서처럼 복잡한 다도구 파이프라인을 필요로 하지 않으며, Qwen-VL과 같은 대규모 다중 모달 LLM과 같이 전체 페이지를 처리하는 엔드투엔드 모델의 비효율성도 피한다. SRR에서는 문서 구문 분석을 세 가지 핵심 질문으로 추상화한다. 즉, “어디에 있나요?”(구조), “무엇인가요?”(인식), “어떻게 구성되어 있나요?”(관계)로, 각각 레이아웃 분석, 콘텐츠 식별, 논리적 순서 정의에 대응한다. 이러한 집중적인 분해는 정확성과 속도 사이의 균형을 유지하며, 정밀도를 희생하지 않으면서도 효율적이고 확장 가능한 처리를 가능하게 한다. 본 접근법의 훈련 및 평가를 위해, 중국어와 영어로 구성된 10종 이상의 문서 유형을 포함하는 총 390만 개의 인스턴스를 보유한 최대 규모의 문서 구문 분석 데이터셋인 MonkeyDoc을 제안한다. 실험 결과, MonkeyOCR는 MinerU 대비 평균 5.1% 높은 성능을 기록했으며, 특히 수식(+15.0%)과 표(+8.6%)와 같은 도전적인 콘텐츠에서 두드러진 개선을 보였다. 놀랍게도, 30억 파라미터 규모의 모델이 Qwen2.5-VL(720억 파라미터)과 Gemini 2.5 Pro와 같은 훨씬 크고 뛰어난 성능을 가진 모델들을 능가하며, 영어 문서 구문 분석 작업에서 최고의 평균 성능을 달성했다. 또한, 다중 페이지 문서 처리 속도에서 MonkeyOCR는 0.84 페이지/초로, MinerU의 0.65 페이지/초와 Qwen2.5-VL-7B의 0.12 페이지/초보다 빠르게 작동한다. 3B 모델은 단일 NVIDIA 3090 GPU에서 효율적인 추론이 가능하도록 배포가 가능하다.