Command Palette
Search for a command to run...
Elizaveta Goncharova Anton Razzhigaev Matvey Mikhalchuk Maxim Kurkin Irina Abdullaeva Matvey Skripkin Ivan Oseledets Denis Dimitrov Andrey Kuznetsov
초록
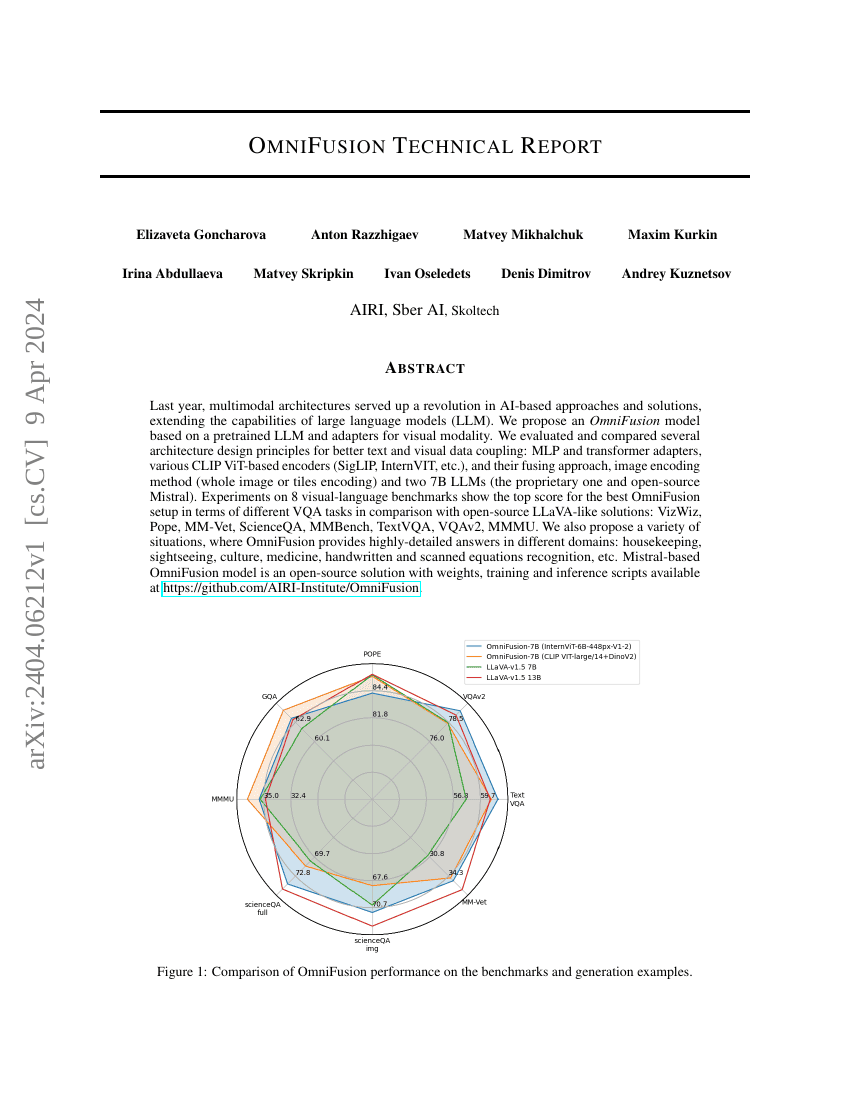
작년, 다중모달 아키텍처는 AI 기반 접근법과 솔루션에서 혁신을 일으켰으며, 대규모 언어 모델(LLM)의 기능을 확장하는 데 기여했다. 본 연구에서는 사전 학습된 LLM과 시각 모달리티를 위한 어댑터를 기반으로 한 '오미포지션(OmniFusion)' 모델을 제안한다. 더 나은 텍스트 및 시각 데이터 간의 통합을 위해 다양한 아키텍처 설계 원칙을 평가하고 비교하였다: MLP 및 트랜스포머 기반 어댑터, 다양한 CLIP ViT 기반 인코더(SigLIP, InternVIT 등), 그들의 융합 방식, 이미지 인코딩 방법(전체 이미지 인코딩 또는 타일 인코딩), 그리고 두 가지 7B 규모의 LLM(특허 모델과 오픈소스 Mistral)을 사용하였다. 8개의 시각-언어 기반 벤치마크에서 실험 결과, 오픈소스 LLaVA 유사 솔루션인 VizWiz, Pope, MM-Vet, ScienceQA, MMBench, TextVQA, VQAv2, MMMU와 비교했을 때, 최적의 오미포지션 설정이 다양한 VQA 작업에서 최고 성능을 기록하였다. 또한 오미포지션 모델이 주방 관리, 관광, 문화, 의료, 손글씨 및 스캔된 수식 인식 등 다양한 분야에서 매우 세밀한 답변을 제공할 수 있는 다양한 시나리오를 제안한다. Mistral 기반 오미포지션 모델은 가중치, 학습 및 추론 스크립트가 모두 공개된 오픈소스 솔루션으로, GitHub에서 제공된다: https://github.com/AIRI-Institute/OmniFusion.
벤치마크
| 벤치마크 | 방법론 | 지표 |
|---|---|---|
| visual-question-answering-on-mm-vet | OmniFusion (grid split + ruDocVQA) | GPT-4 score: 39.40 |