효율적이고 효과적인 텍스트-비디오 검색을 위한 대략적에서 세부적인 시각적 표현 학습
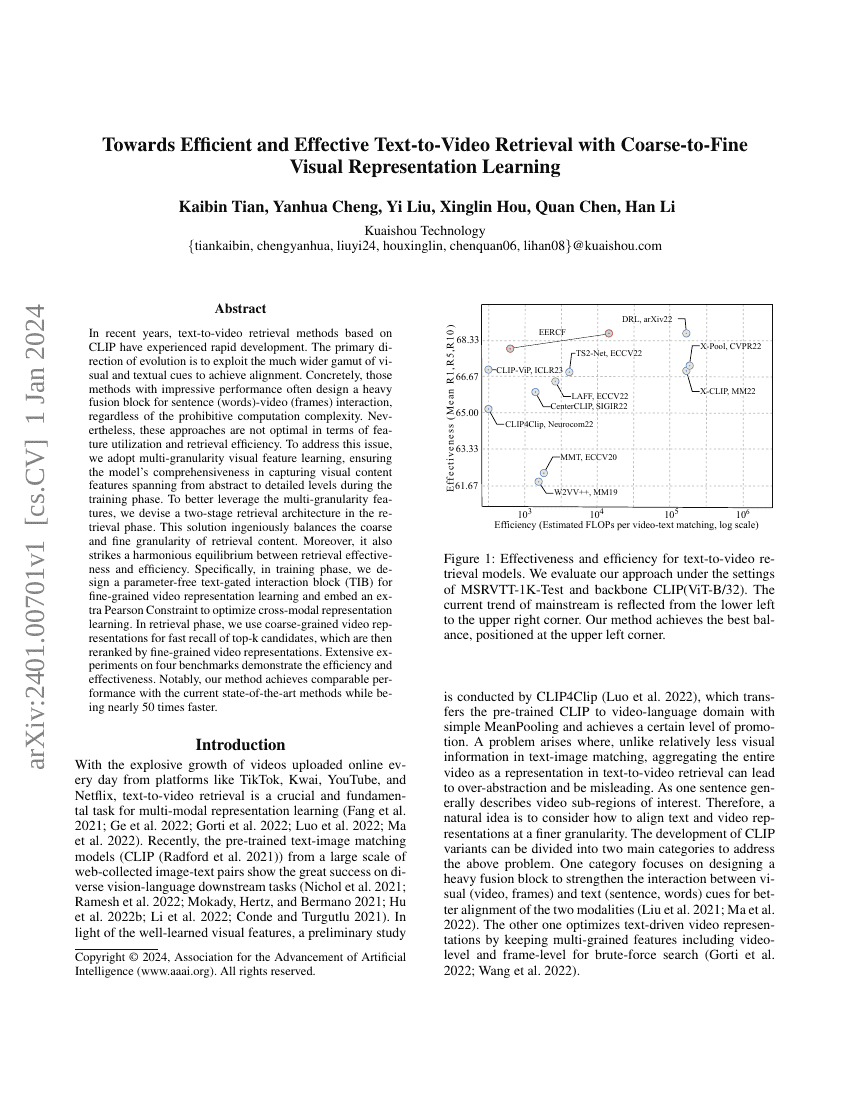
최근 몇 년간 CLIP 기반의 텍스트-비디오 검색 방법이 급속히 발전하고 있습니다. 진화의 주요 방향은 시각적 및 텍스트적 신호의 더 넓은 범위를 활용하여 정렬을 달성하는 것입니다. 구체적으로, 인상적인 성능을 보이는 이러한 방법들은 대부분 문장(단어)-비디오(프레임) 상호작용을 위해 복잡한 융합 블록을 설계하지만, 이는 계산 복잡도가 매우 높다는 단점이 있습니다. 그럼에도 불구하고, 이러한 접근 방식은 특징 활용과 검색 효율성 측면에서 최적이지 않습니다. 이 문제를 해결하기 위해 우리는 다중 세분화 시각 특징 학습을 채택하여, 훈련 단계에서 추상적 수준부터 세부적 수준까지의 시각 콘텐츠 특징을 포착하는 모델의 포괄성을 보장합니다. 다중 세분화 특징을 더 효과적으로 활용하기 위해, 검색 단계에서는 두 단계 검색 아키텍처를 설계하였습니다. 이 솔루션은 창의적으로 검색 내용의 거시적과 미시적 세분화를 균형 있게 조절하며, 또한 검색 효과와 효율성 사이에 조화로운 균형을 이루고 있습니다. 특히, 훈련 단계에서는 파라미터 없는 텍스트 게이트 상호작용 블록(TIB)을 설계하여 미시적 비디오 표현 학습을 수행하고, 추가로 피어슨 제약(Pearson Constraint)을 내장하여 다중 모달 표현 학습을 최적화하였습니다. 검색 단계에서는 거시적 비디오 표현을 사용하여 상위 k개 후보를 빠르게 추출한 후, 이를 미시적 비디오 표현으로 재정렬합니다. 네 가지 벤치마크에서 실시된 광범위한 실험 결과는 이 방법의 효율성과 효과성을 입증하였습니다. 특히, 우리 방법은 현재 최신 기술들과 비교할 만한 성능을 달성하면서 거의 50배 더 빠른 것으로 나타났습니다.