SegViTv2: 효율적이고 지속적인 의미 분할을 위한 일반 비전 트랜스포머 탐구
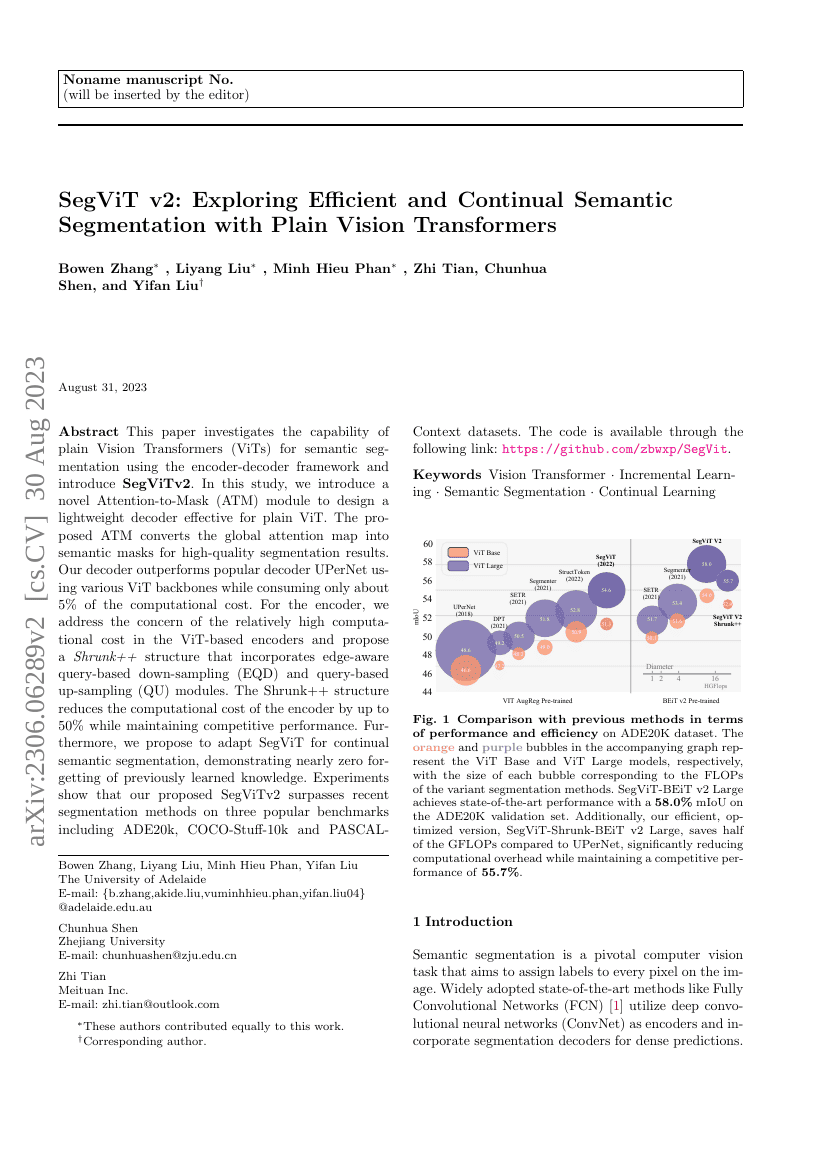
본 논문은 인코더-디코더 프레임워크를 사용하여 시맨틱 세그멘테이션을 위한 일반적인 비전 트랜스포머(Vision Transformers, ViTs)의 성능을 조사하고 \textbf{SegViTv2}를 소개합니다. 본 연구에서는 일반적인 ViT에 효과적인 경량 디코더를 설계하기 위해 새로운 \emph{어텐션-마스크(Attention-to-Mask, ATM)} 모듈을 제안합니다. 제안된 ATM은 글로벌 어텐션 맵을 고품질의 시맨틱 마스크로 변환합니다. 우리의 디코더는 다양한 ViT 백본을 사용할 때 인기 있는 UPerNet 디코더보다 우수한 성능을 보이며, 계산 비용은 약 5%만 소비합니다.인코더 부분에서는 ViT 기반 인코더의 상대적으로 높은 계산 비용 문제를 해결하기 위해 엣지 인식 쿼리 기반 다운샘플링(Edge-Aware Query-based Down-sampling, EQD)과 쿼리 기반 업샘플링(Query-based Upsampling, QU) 모듈을 통합한 \emph{Shrunk++} 구조를 제안합니다. Shrunk++ 구조는 경쟁력 있는 성능을 유지하면서 인코더의 계산 비용을 최대 50%까지 줄일 수 있습니다.또한, 우리는 SegViT를 연속 학습 시맨틱 세그멘테이션에 적응시키는 방법을 제안하며, 이는 이전에 학습된 지식의 거의 완벽한 기억력을 보여줍니다. 실험 결과, 제안된 SegViTv2는 ADE20k, COCO-Stuff-10k 및 PASCAL-Context 데이터셋 등 세 가지 유명 벤치마크에서 최근의 세그멘테이션 방법들을 능가하는 것으로 나타났습니다. 코드는 다음 링크에서 제공됩니다: \url{https://github.com/zbwxp/SegVit}.