비디오 인식을 위한 학습 가능한 정렬을 통한 은유적 시계열 모델링
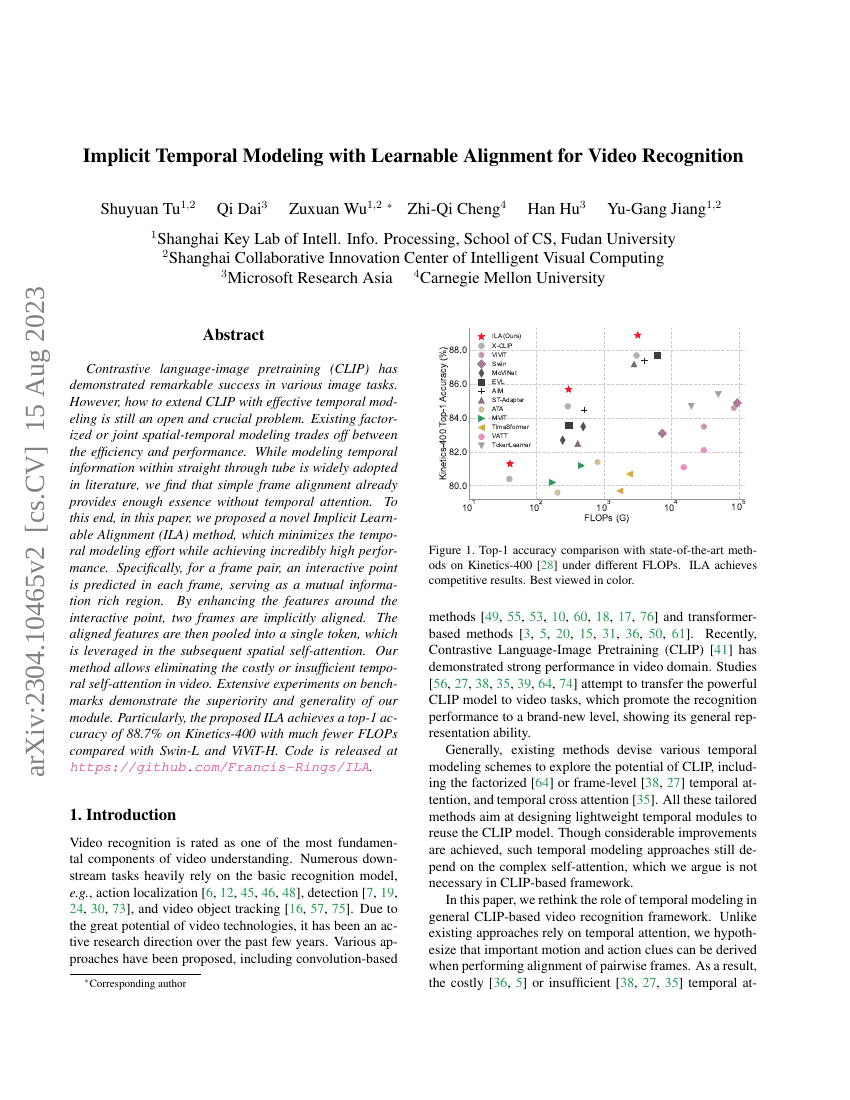
대조적 언어-이미지 사전학습(Contrastive Language-Image Pretraining, CLIP)은 다양한 이미지 작업에서 뛰어난 성과를 보여주었으나, 효과적인 시계열 모델링을 통해 CLIP를 확장하는 방법은 여전히 열려 있고 핵심적인 과제로 남아 있다. 기존의 분리형 또는 결합형 공간-시계열 모델링은 효율성과 성능 사이에서 트레이드오프를 경험한다. 문헌에서 일반적으로 채택되는 직선형 튜브 내 시계열 정보 모델링은 단순한 프레임 정렬만으로도 충분한 본질적인 정보를 제공함을 우리는 발견하였다. 이를 바탕으로 본 논문에서는 시계열 모델링에 드는 부담을 최소화하면서도 놀라운 성능을 달성하는 새로운 은닉 가변 정렬(Implied Learnable Alignment, ILA) 방법을 제안한다. 구체적으로, 프레임 쌍에 대해 각 프레임 내에서 상호작용 포인트를 예측하고, 이 포인트 주변의 특징을 강화함으로써 두 프레임을 은닉적으로 정렬한다. 이 정렬된 특징은 이후 공간 자기주목(self-attention)에 활용될 수 있도록 단일 토큰으로 풀링된다. 본 방법은 동영상 처리에서 비용이 크거나 충분하지 않은 시계열 자기주목을 제거할 수 있게 한다. 다양한 벤치마크에서 실시한 광범위한 실험을 통해 제안한 모듈의 우수성과 일반성(일반화 능력)을 입증하였다. 특히, Swin-L 및 ViViT-H 대비 훨씬 적은 FLOPs로 Kinetics-400 데이터셋에서 상위-1 정확도 88.7%를 달성하였다. 코드는 https://github.com/Francis-Rings/ILA 에 공개되어 있다.