가상 희소 컨볼루션을 이용한 다중 모달 3D 객체 검출
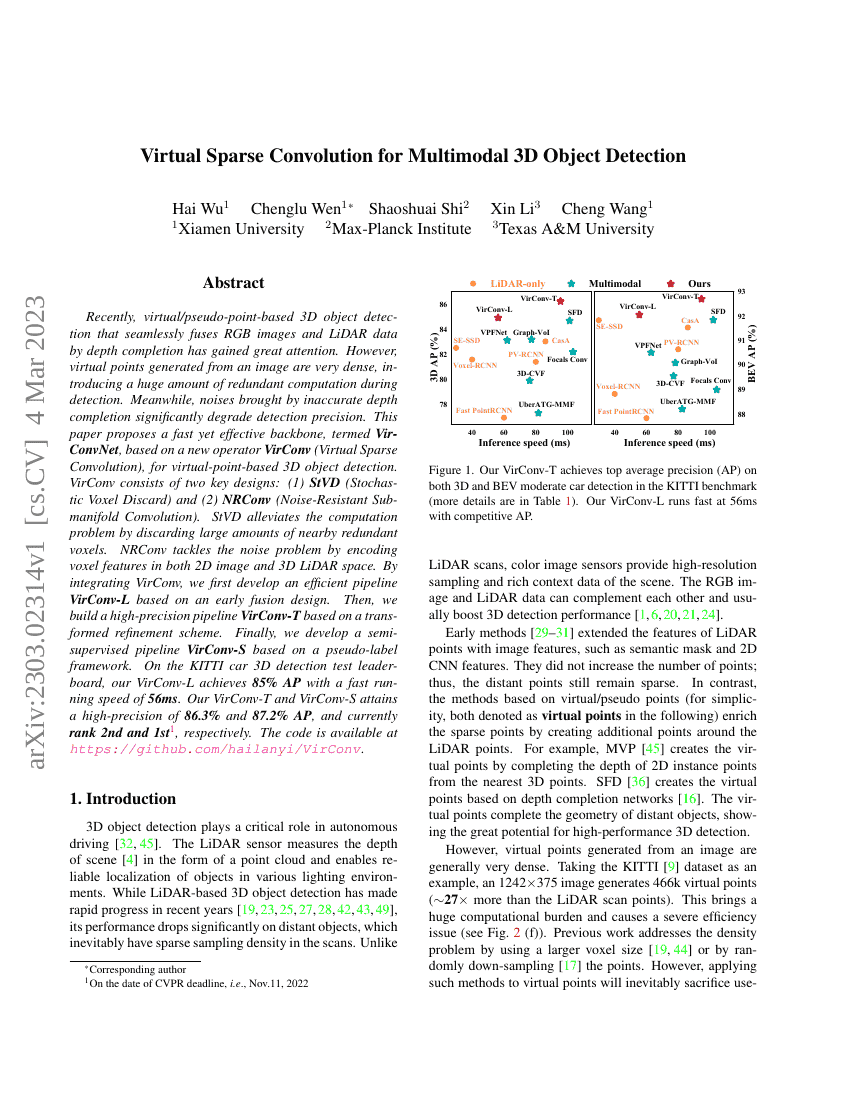
최근, 깊이 완성(dept completion)을 통해 RGB 이미지와 LiDAR 데이터를 원활하게 융합하는 가상/가상 포인트 기반 3D 객체 검출이 큰 주목을 받고 있습니다. 그러나 이미지에서 생성된 가상 포인트는 매우 밀도가 높아, 검출 과정에서 막대한 양의 중복 계산을 초래합니다. 또한, 부정확한 깊이 완성으로 인해 발생하는 노이즈는 검출 정밀도를 크게 저하시킵니다. 본 논문에서는 이러한 문제를 해결하기 위해 새로운 연산자인 VirConv (Virtual Sparse Convolution)을 기반으로 한 빠르면서도 효과적인 백본 네트워크인 VirConvNet을 제안합니다. VirConv은 두 가지 핵심 설계로 구성됩니다: (1) StVD (Stochastic Voxel Discard)와 (2) NRConv (Noise-Resistant Submanifold Convolution). StVD는 많은 양의 근접 중복 복셀(voxel)을 버림으로써 계산 문제를 완화합니다. NRConv는 2D 이미지 공간과 3D LiDAR 공간에서 복셀 특성을 인코딩하여 노이즈 문제를 해결합니다.VirConv을 통합하여, 먼저 초기 융합 설계를 기반으로 효율적인 파이프라인인 VirConv-L을 개발하였습니다. 그 다음, 변환된 정교화 방식을 기반으로 고정밀 파이프라인인 VirConv-T를 구축하였습니다. 마지막으로, 의사 라벨(pseudo-label) 프레임워크를 기반으로 반감독(semi-supervised) 파이프라인인 VirConv-S를 개발하였습니다. KITTI 자동차 3D 검출 테스트 리더보드에서 우리의 VirConv-L은 56ms의 빠른 실행 속도로 85%의 AP(Average Precision)를 달성하였습니다. 또한, VirConv-T와 VirConv-S는 각각 86.3%와 87.2%의 고정밀 AP를 달성하여 현재 각각 2위와 1위에 올라있습니다. 코드는 https://github.com/hailanyi/VirConv에서 확인할 수 있습니다.