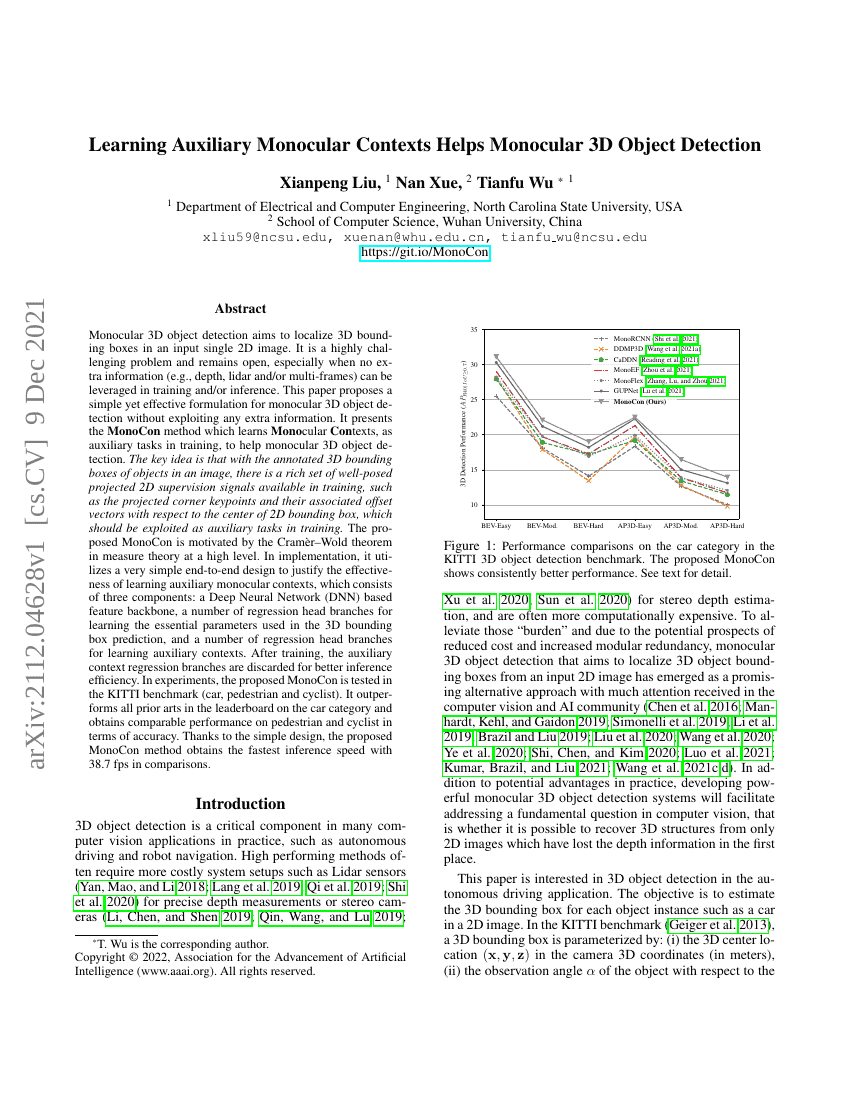
단안 3차원 객체 탐지( monocular 3D object detection)는 입력된 단일 2차원 이미지 내에서 3차원 경계상자(3D bounding box)를 탐지하는 것을 목표로 한다. 이는 매우 도전적인 문제이며, 특히 학습 및/또는 추론 과정에서 깊이(depth), 라이다(lidar), 다중 프레임(multi-frames) 등의 추가 정보를 활용할 수 없는 경우 더욱 열린 문제로 남아 있다. 본 논문은 어떠한 추가 정보도 활용하지 않고도 효과적인 단안 3차원 객체 탐지 방식을 제안한다. 제안하는 MonoCon 방법은 학습 과정에서 보조 작업(auxiliary tasks)으로서 단안 맥락(monocular contexts)을 학습함으로써 단안 3차원 객체 탐지의 성능을 향상시키는 것을 핵심 아이디어로 한다. 주요 개념은 이미지 내 객체의 레이블링된 3차원 경계상자 정보를 바탕으로, 학습 시 잘 정의된 2차원 투영된 감독 신호(projection supervision signals)가 풍부하게 존재한다는 점에 있다. 예를 들어, 2차원 경계상자의 중심과 관련된 투영된 꼭짓점 키포인트(corner keypoints) 및 그들의 오프셋 벡터(offset vectors) 등이 이러한 보조 작업으로 활용될 수 있다. 제안된 MonoCon은 측도 이론(measure theory)의 크라머-월드 정리(Cramer-Wold theorem)에 기반하여 고도로 설계되었다. 구현 측면에서는 보조 단안 맥락을 학습하는 효과를 입증하기 위해 매우 간단한 엔드투엔드(end-to-end) 설계를 사용한다. 이 설계는 세 가지 구성 요소로 이루어져 있다: 딥 신경망(DNN) 기반의 특징 백본(feature backbone), 3차원 경계상자 예측에 사용되는 핵심 파라미터를 학습하기 위한 회귀 헤드 브랜치들, 그리고 보조 맥락을 학습하기 위한 회귀 헤드 브랜치들이다. 학습이 완료된 후에는 보조 맥락 회귀 브랜치들을 제거함으로써 추론 효율성을 더욱 높일 수 있다. 실험에서는 KITTI 벤치마크(자동차, 보행자, 자전거 탑승자)에서 제안된 MonoCon을 평가하였으며, 자동차 카테고리에서는 기존 모든 기법들을 초월하는 성능을 보였고, 보행자 및 자전거 탑승자 카테고리에서도 정확도 측면에서 경쟁 가능한 성능을 달성하였다. 간단한 설계 덕분에 MonoCon은 비교 대상 중 가장 빠른 추론 속도인 38.7 fps를 기록하였다.