비전 분야에서 실제로 필요한 것은 메타포머(metaformer)입니다.
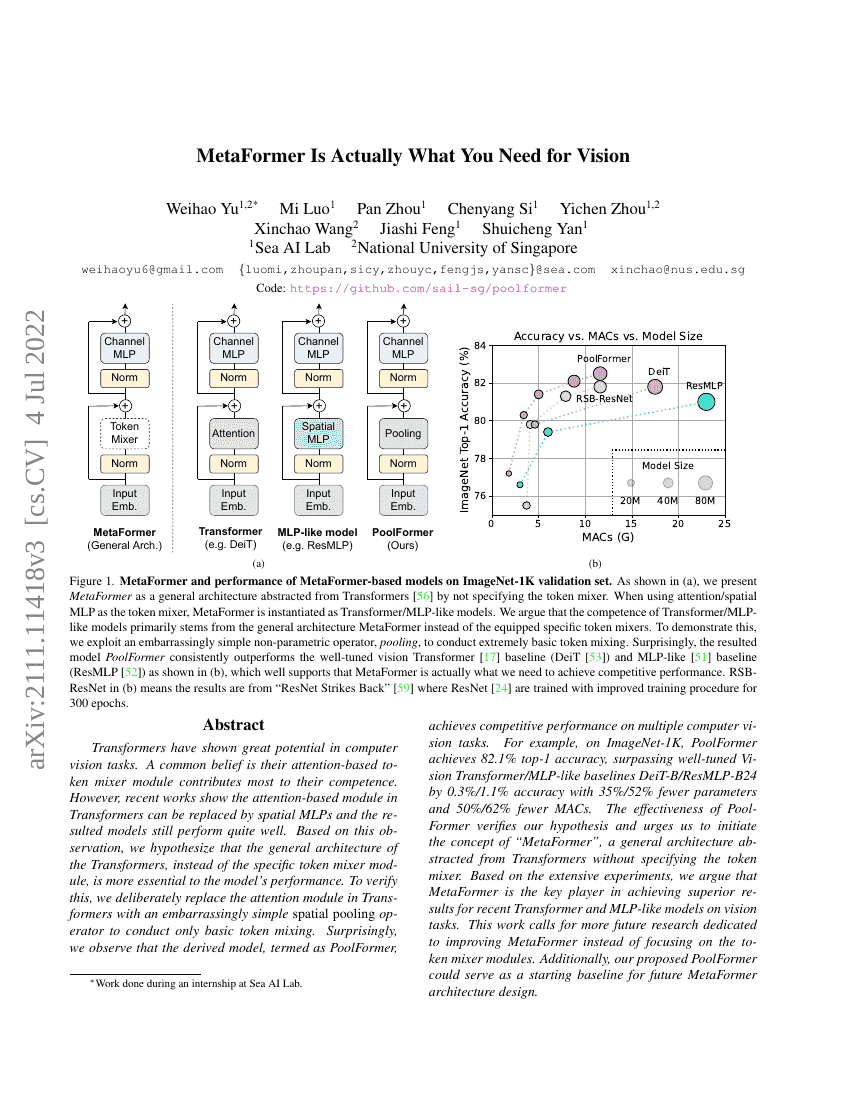
Transformers는 컴퓨터 비전 작업에서 큰 잠재력을 보여주고 있다. 일반적으로 인지 기반의 토큰 믹서 모듈이 그 성능의 핵심 요소라고 여겨져 왔다. 그러나 최근 연구들은 Transformers 내의 인지 기반 모듈을 공간적 MLP(spatial MLPs)로 대체하더라도 모델이 여전히 우수한 성능을 발휘할 수 있음을 보여주고 있다. 이러한 관찰을 바탕으로, 우리는 Transformers의 일반적인 아키텍처 자체가 모델 성능에 더 중요한 역할을 한다고 가정한다. 이를 검증하기 위해, Transformers의 인지 모듈을 매우 단순한 공간 풀링 연산자로 의도적으로 대체하여 최소한의 토큰 믹싱만 수행하도록 하였다. 놀랍게도, 이를 통해 도출된 모델인 PoolFormer이 여러 컴퓨터 비전 작업에서 경쟁력 있는 성능을 달성함을 관찰하였다. 예를 들어, ImageNet-1K에서 PoolFormer은 82.1%의 top-1 정확도를 기록하며, 잘 튜닝된 Vision Transformer 및 MLP 유사 기반 모델인 DeiT-B 및 ResMLP-B24보다 각각 0.3%, 1.1% 높은 정확도를 달성하였으며, 파라미터 수는 35%, 52% 줄이고, MACs(Multiply-Accumulate Operations)는 50%, 62% 감소시켰다. PoolFormer의 효과성은 우리의 가정을 뒷받침하며, 'MetaFormer'이라는 개념을 제안하게 되었다. MetaFormer은 토큰 믹서 모듈을 구체적으로 정의하지 않은, Transformers에서 추상화된 일반적인 아키텍처이다. 광범위한 실험을 바탕으로, 우리는 최근 Transformer 및 MLP 유사 모델이 비전 작업에서 우수한 성능을 내는 데 있어 MetaFormer이 핵심적인 역할을 한다고 주장한다. 본 연구는 토큰 믹서 모듈에 집중하기보다는 MetaFormer의 개선에 더 많은 미래 연구를 투자할 것을 촉구한다. 또한, 제안한 PoolFormer은 향후 MetaFormer 아키텍처 설계의 기초 기준(baseline)으로 활용될 수 있다. 코드는 https://github.com/sail-sg/poolformer 에서 공개되어 있다.